IPC 管道(pipe)测试
基础知识梳理
文件共享
unix系统支持在不同进程间共享打开文件。下面两个函数都可以用来复制一个现有的文件描述符1
2
3
int dup(int fd);
int dup2(int fd, int fd2);
由dup返回的新文件描述符一定是当前可用文件描述符中的最小数值。
对于dup2,可以用fd2参数指定新描述符的值。
- 如果fd2已经打开,则先将其关闭;
- 如若fd等于fd2,则dup2返回fd2,而不关闭它;
- 否则,fd2的FD_CLOEXEC文件描述符标志就被清除,这样fd2在进程调用exec时是打开状态
这些函数返回的新文件描述符与参数fd共享同一个文件表项。
fork进程
一个现有的进程可以调用fork函数创建另一个新进程。1
2
pid_t fork(void);
由fork创建的新进程被称为子进程(child process)。fork函数被调用一次,但返回两次。两次返回的区别是子进程返回值是0,父进程的返回值是新建子进程的进程ID。因为一个父进程可以有多个子进程,并且没有一个函数使一个进程可以获得其所有子进程的ID;而子进程只有一个父进程,子进程总是可以通过调用getppid获得其父进程的进程ID。
子进程和父进程继续执行fork调用之后的指令。子进程是父进程的副本,可以获得父进程的数据空间、堆和栈的副本。父进程的所有打开文件描述符都被复制到子进程中,我们说“复制”是因为对每个文件描述符来说,就好像执行了dup函数。父进程和子进程每个相同的打开文件描述符共享一个文件表项。一般来说,在fork之后是父进程先执行还是子进程先执行是不确定的,这取决于内核所使用的调度算法。
在fork之后处理文件描述符有以下两种常见的情况:
- 父进程等待子进程完成。在这种情况下,父进程无需对其描述符做任何处理,当子进程终止后,它曾进行读、写操作的任何共享描述符的文件偏移量已做了相应更新。
- 父进程和子进程各自执行不同的程序段。在这种情况下,在fork之后,父进程和子进程各自关闭它们不需要使用的文件描述符,这样就不会干扰对方使用的文件描述符。这种方法是网络服务进程经常使用的。
函数exec
用fork函数创建新的子进程之后,子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程执行的程序完全替换为新程序,而新程序则从其main函数开始执行。因为调用exec并不创建新进程,所以前后的进程ID并未改变。exec只是用磁盘上的一个新程序替换了当前进程的正文段、数据段、堆段和栈段。1
2
int execv(const char *pathname, char* const argv[]);
用fork可以创建新进程,用exec可以初始执行新的程序;exit函数和wait函数处理终止和等待终止。这些是我们需要的基本的进程控制原语。
管道IPC
管道是unix系统IPC的最古老形式,所有unix系统都提供此种通信机制。管道又分为匿名管道和命名管道:
- 匿名管道(pipe),是一种半双工的通信方式,数据只能单向流动,而且只能在具有公共祖先的进程间使用,通常是指父子进程间。
- 命名管道(named pipe),又叫FIFO(First In, First Out),通常也是半双工的通信方式,不同的是,命名管道可以支持没有亲缘关系的进程之间通信。
- FIFO (First in, First out)为一种特殊的文件类型,它在文件系统中有对应的路径,因此可以通过文件的路径来识别管道,从而让没有亲缘关系的进程之间建立连接,可以用函数mkfifo()创建。
大家通常说的管道默认情况下是指匿名管道,可以通过pipe函数创建:1
2
int pipe(int fd[2]);
经由参数fd返回两个文件描述符:fd[0]为读而打开,fd[1]为写而打开.fd[1]的输出是fd[0]的输入。如下图所示: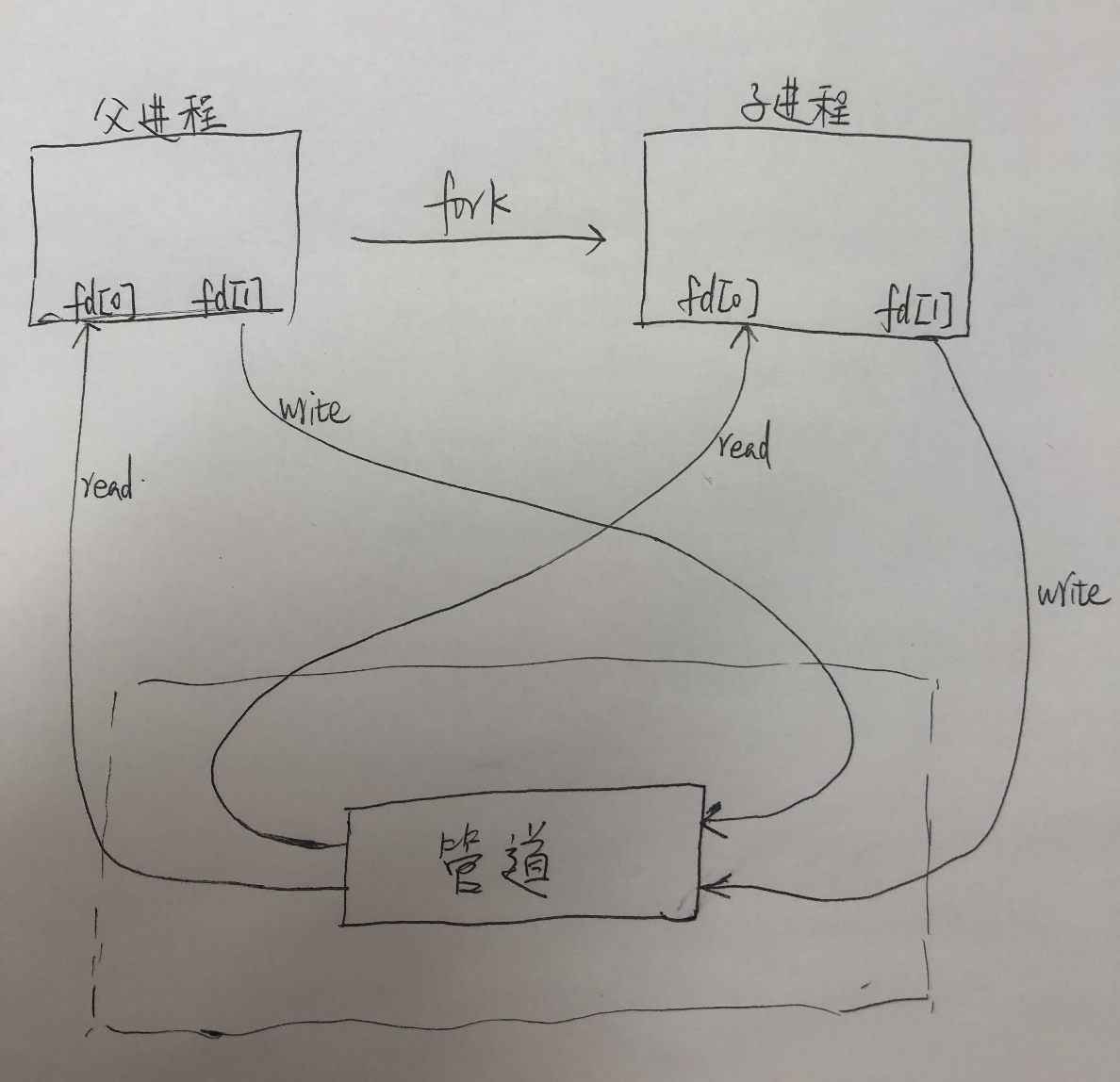
对于从父进程到子进程的管道,父进程关闭管道的读端(fd[0]),子进程关闭管道的写端(fd[1]);对于从子进程到父进程的管道,父进程关闭fd[1],子进程关闭fd[0]。当管道的一段被关闭后,下列两条规则起作用:
- 当读(read)一个写端已被关闭的管道时,在所有数据都被读取后,read返回0,表示文件结束
- 如果写(write)一个读端已被关闭的管道时,则产生信号SIGPIPE。如果忽略该信号或者捕捉该信号并从其处理程序返回,则write返回-1,errno被设置为EPIPE。
管道测试
下面主要测试下父子进程通过匿名管道进行通信的过程:子进程写,父进程读,因此关闭了父进程的写文件描述符和子进程的读文件描述符;主要想看一下,如果管道中没有数据,读操作是否会被阻塞,还是直接返回。
子进程代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
using namespace std;
string get_time()
{
char buff[30]; // sizeof("2018-04-19 19:49:23") == 20;
time_t now = time(NULL);
struct tm *local_time = NULL;
local_time = localtime(&now);
strftime(buff, sizeof(buff), "%Y-%m-%d %H:%M:%S ", local_time);
return string(buff);
}
void test() {
cerr << get_time() << "[sub process] begin to sleep" << endl;
sleep(30);
cerr << get_time() << "[sub process] begin to output" << endl;
int cnt = 0;
while (1) {
++cnt;
printf("word %10d", cnt);
//cout << "word " << to_string(cnt) << endl;
cerr << get_time() << "[sub process] begin to usleep" << endl;
usleep(100000);
}
}
int main() {
test();
return 0;
}
# 编译链接
/opt/compiler/gcc-8.2/bin/g++ --std=c++11 ./sub_process.cpp -o sub_process
主进程代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
using namespace std;
string get_time()
{
char buff[30]; // sizeof("2018-04-19 19:49:23") == 20;
time_t now = time(NULL);
struct tm *local_time = NULL;
local_time = localtime(&now);
strftime(buff, sizeof(buff), "%Y-%m-%d %H:%M:%S ", local_time);
return string(buff);
}
void test() {
cerr << get_time() << " main process" << endl;
cerr << get_time() << " fork sub process" << endl;
FILE* sub_stdin; // user progress stdin --> can write
FILE* sub_stdout; // user progress stdout --> can read
int infd[2]; //文件描述符, [0]读管道,[1]写管道
pipe(infd);
const char* cmd = "./sub_process";
int pid = fork();
if (pid == -1) {
printf("fork error happens: %s\n", strerror(errno));
close(infd[0]);
close(infd[1]);
} else if (pid == 0) {
cerr << get_time() << "-----[sub process]-----" << endl;
// copy to std
int temp_fd;
if ((temp_fd = dup2(infd[1], 1)) != 1) {
fprintf(stderr, "err when dup2 infd 0, return= %d, infd0= %d\n", temp_fd, infd[0]);
}
close(infd[0]);
close(infd[1]);
fprintf(stderr, "BEFORE execv, cmd=[ %s ]\n", cmd);
// start user cmd
const char* args[] = { "/bin/bash", "-c", cmd, NULL };
if (-1 == execv(args[0], (char * const*)args)) {
fprintf(stderr, "Error when execv: %s\n", strerror(errno));
}
} else {
cerr << get_time() << "-----[parent process]-----" << endl;
close(infd[1]); // only read, close write
fprintf(stderr, "SUCCESS fork, pid=[ %d ], cmd=[ %s ]\n", pid, cmd);
sub_stdout = fdopen(infd[0], "r");
while (1) {
char buf[20];
cerr << get_time() << "[parent process] before read pipe" << endl;
int ret = fread(buf, 15, 1, sub_stdout);
cerr << get_time() << "[parent process] after read pipe" << endl;
if (ret != 1) {
cerr << get_time() << "[parent process] read error " << ret << endl;
cerr << get_time() << "[parent process] begin to usleep 1000" << endl;
usleep(1000);
} else {
buf[16] = '\0';
fprintf(stderr, "%s [parent process] read buf: %s\n", get_time().c_str(), buf);
}
}
}
}
int main() {
test();
return 0;
}
# 编译链接
/opt/compiler/gcc-8.2/bin/g++ --std=c++11 ./main_process.cpp -o main_process
运行结果如下: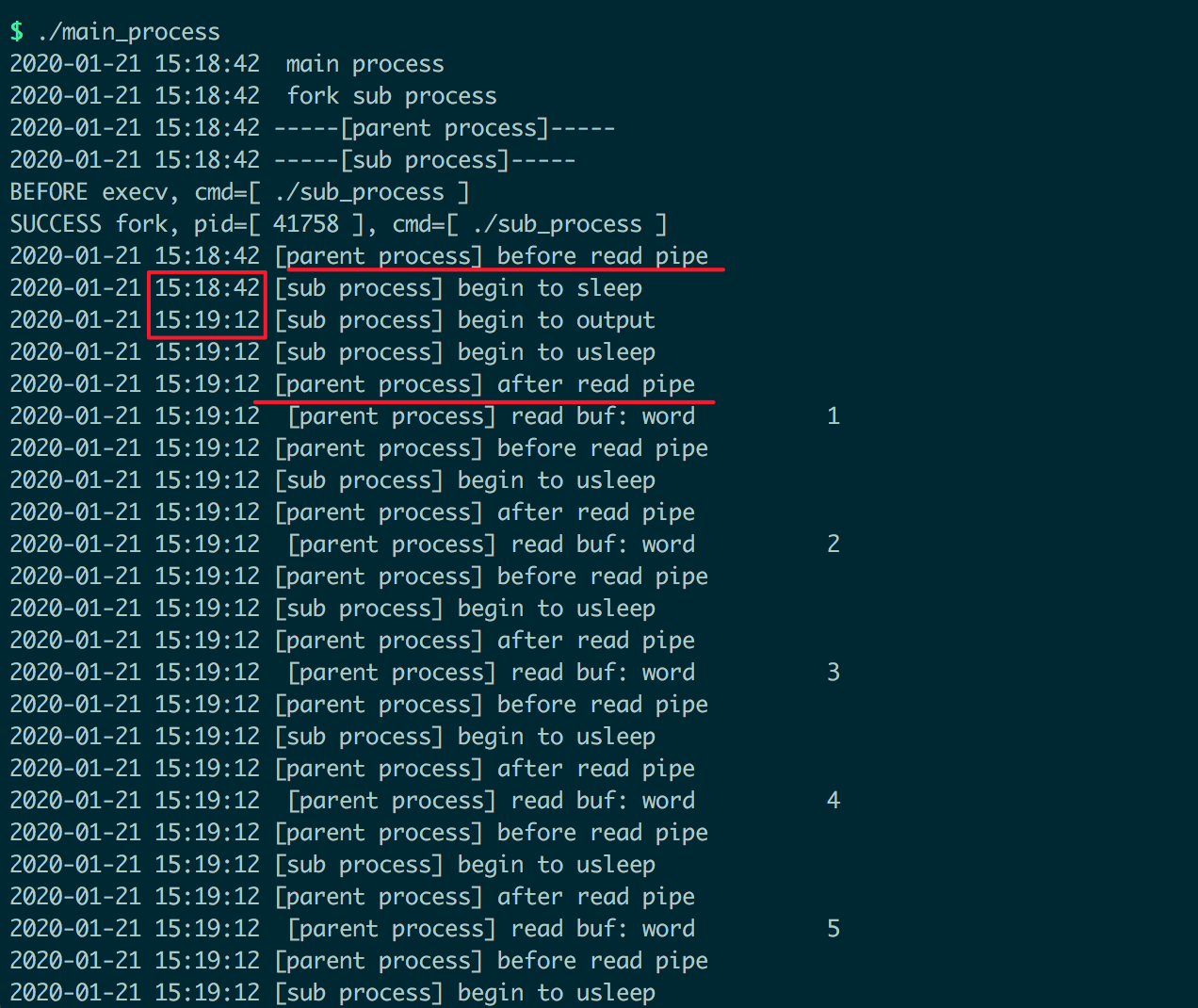
总结
实验表明,通过匿名管道进行父子进程的数据通信时,如果管道为空,读操作会被阻塞。
[未完待续!]
Refer
- 《UNIX环境高级编程》
Flink Forward Asia 参会总结
2019.11.28~2019.11.29 参加了Flink Forward Asia 2019大会,大家对实时计算热情很高,参会人数及企业都很多。会议一共持续一天半,第一天上午是主会场,第一天下午和第二天上午是分会场,分会场的话有核心技术、企业实践、实时数仓、开源大数据生态、人工智能五个分会场并行,我主要穿梭在核心技术和实时数仓两个分会场。下面先简单介绍下Flink的前世今生,以及会场上我听的几个topic.
Flink 发展历程
- Apache Flink项目在捐献给Apache之前,是由柏林工业大学博士生发起的项目,当时的Flink系统还是一个基于流式Runtime的批处理引擎,主要解决的也是批处理的问题。
- 2014年,Flink被捐献给Apache,并迅速成为Apache 的顶级项目之一。
- 2014年8月份,Apache发布了第一个Flink版本,Flink 0.6.0,在有了较好的流式引擎支持后,流计算的价值也随之被挖掘和重视;同年12月,Flink发布了0.7版本,正式推出了DataStream API,这也是目前Flink应用的最广泛的API。
- Flink 0.9中引入了Global Checkpoint机制以保证exactly-once语义,主要基于经典的Chandy-Lamport算法进行的改进。Flink 会在数据源中定期插入Barrier,框架在看到 Barrier 后会对本地的 State 做一个快照,然后再将 Barrier 往下游发送。
- Flink 1.0 版本加入了基于事件时间的计算支持,引入了 Watermark 机制,可以高效的容忍乱序数据和迟到数据。Flink 1.0同时还内置支持了各种各样的 window,开箱即用的滚动、滑动、会话窗口等,还可以灵活地自定义窗口。
- 2015年之后,阿里巴巴开始注意到 Flink 计算引擎,并且非常认可 Flink 系统设计理念的先进性,看好其发展前景,因此阿里巴巴内部开始大量使用 Flink,同时也对 Flink 做了大刀阔斧的改进,形成了内部版,即Blink
- 2018 年双 11,阿里巴巴Flink服务规模已经超过万台集群。单作业已经达到了数十 TB 的状态数据,所有的作业加起来更是达到了 PB 级。每天需要处理超过十万亿的事件数据。在双 11 的零点峰值时,数据处理量已经达到了 17 亿条每秒。
- 目前 Flink 最新的版本是1.9,Flink 在这个版本上做了较大的架构调整。首先,Flink 之前版本的 Table API 和 SQL API 是构建于两个底层的API 之上,即 DataStream API 和 DataSet API。Flink 1.9 经历了较大的架构调整之后,Table API 和 DataStream API 已成为同级的 API。不同之处在于 DataStream API 提供的是更贴近物理执行计划的 API,引擎完全基于用户的描述能执行作业,不会过多的进行优化和干预。Table API 和 SQL 是关系表达式 API,用户使用这个 API 描述想要做一件什么事情,由框架在理解用户意图之后,配合优化器翻译成高效的具体
执行图。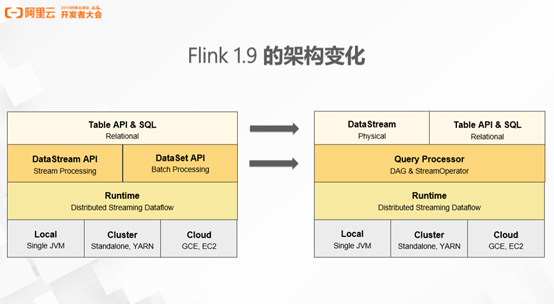
详见:https://yq.aliyun.com/articles/712192?type=2
引擎一体化和生态多元化是 Flink 一以贯之的发展策略。引擎一体化指的是离线(batch),实时(streaming)和在线(application)应用在执行层面的一体化。生态多元化指的是对 AI 生态环境的搭建和对更多生态的支持,包括 Hive,Python,Kubernetes 等。
主会场
1. Stateful Functions:Building general-purpose Applications and Services on Apache Flink
Stephan 继续推广他对 Flink 作为应用服务场景(Applications and Services)通用引擎的展望和规划。简而言之,他认为 Flink 除了能够做到批流一体,Flink 框架对于事件驱动的在线应用也可以有效甚至更好的支持,如下图所示:
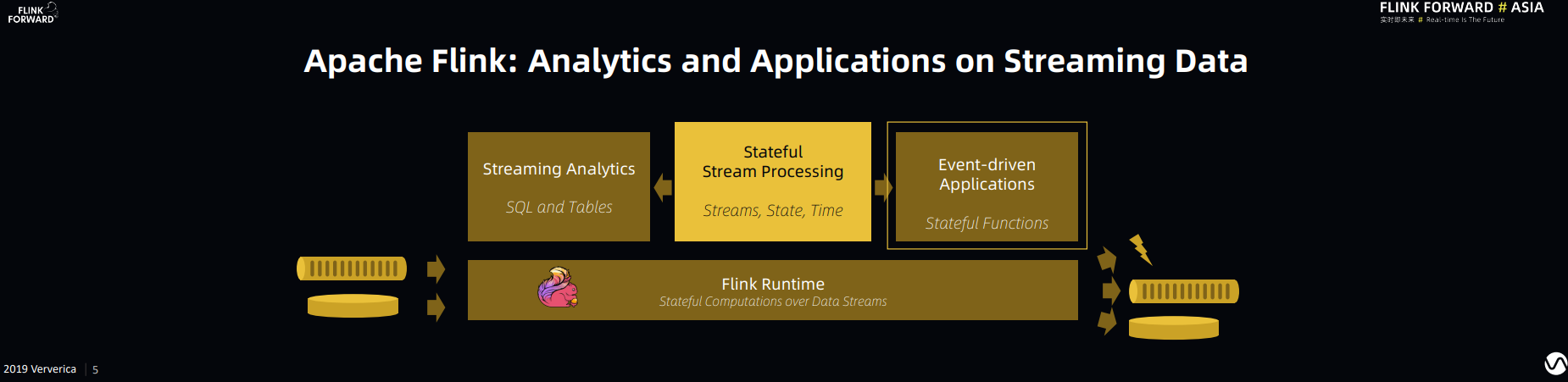
云上对此类问题的一种主流的解决方案便是FaaS。FaaS是Function as a Service的缩写,可以简单理解为功能服务化。FaaS提供了一种比微服务更加服务碎片化的软件架构范式。FaaS可以让研发只需要关注业务代码逻辑,不再关注技术架构。以微服务为核心的前后端分离,业务积木装配式技术架构。但目前仍有以下几个方面的痛点:
(1)Bottlenecked by state access & I/O
(2)State Consistency Problem
(3)Scalability of Database (storing the states)
(4)Connections and Request rates
特别是在应用逻辑非常复杂的情况下,应用逻辑之间的组合调用会更加复杂,并且加剧上面四个痛点的复杂度。同时你会发现上面的这些问题都和State 的存储(storage),读写(access)以及一致性(consistency)相关,而 Flink 的 Stream Processing 框架可以很好的解决这些和状态相关的问题。所以 Stateful Function 在 Flink 现有的框架上拓展了对 Function Composition 和 Virtual Instance(轻量级的 Function 资源管理)的支持,以达到对应用服务场景(Application)的通用支持。

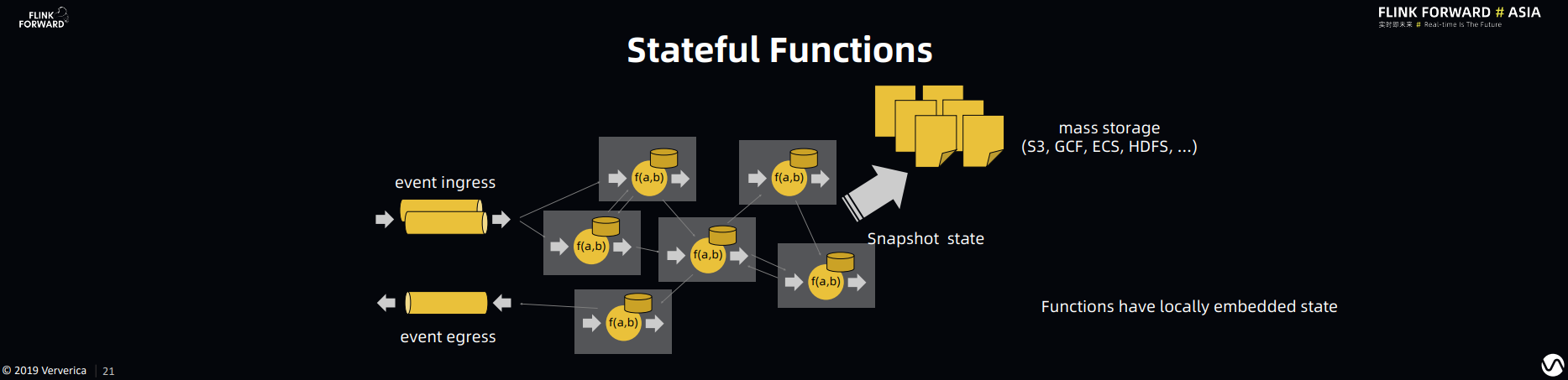
可以从两个维度理解 Stateful Function:
1. Stateful Function 到底要解决什么问题
2. 为什么 Stateful Function 比现有的解决方案更好
关于第一个问题举例说明,假设我们使用Lyft打车服务。在乘客发起打车请求以后,Lyft 首先会根据乘客的定位,空闲司机的状态,目的地,交通状况和个人喜好给乘客推荐不同类型车辆的定价。在乘客选择定价以后,Lyft 会根据乘客的喜好(比如有些司机被乘客拉了黑名单),司机的喜好(乘客也有可能被司机拉了黑名单),司机和乘客的相对位置以及交通状况进行匹配,匹配完成后订单开始。在这个例子中,我们会发现:
- 有很多 Function Composition:乘客的喜好的计算,司机的喜好计算,司机和乘客相对位置计算,交通状况计算,以及最终匹配计算,这些计算都是带有状态的计算
- 状态的一致性的重要:在匹配的过程中如果发生错误,在保持状态一致性的情况下回滚非常重要。我们不希望一个乘客匹配给两个司机,也不希望一个司机匹配给两个乘客,更不希望乘客或者司机因为一致性问题无法得到匹配。
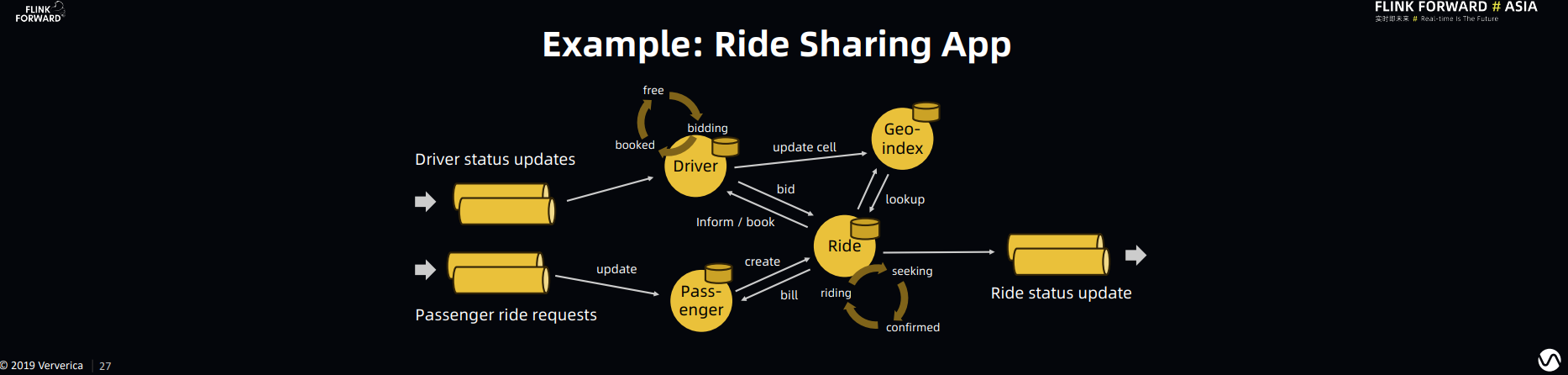
Stateful Function 在 Flink 开源 Runtime 的基础上很好的解决了 Function Composition 和 State Consistency 的问题。
关于第二个问题:为什么 Stateful Function 比现有的解决方案更好。我的理解是 Stateful Function 提供了更清晰的 abstraction。Stateful Function 把消息传输、状态管理从 Function 中隔离出来,使得用户只需要关注 Function 计算逻辑本身,而不需要关注 Function 的调度,组合等问题,这也使得Stateful Function 框架能有更多的自由度为 Function 调度组合等问题做优化。
关于打车,我记得Uber要用Flink做实时异常检测,检测司机或乘客是否发生了车祸
FaaS的具体技术实现以及如何实现Function之间任意通信(不限于DAG)我还不太清楚,后面有时间再看一下
2. Apache Flink Heading Towards A Unified Engine
阿里实时计算负责人莫问认为未来 Flink 的发展趋势是一体化:包括离线(batch),实时(streaming)和在线(application)一体化。在此基础上,也需要把拥抱 AI 和云原生纳入到一体化中。
对于批流融合,通过 1.9 和 1.10 两个版本的发布,Flink 在 SQL 和 Table API 的层面以及 Flink runtime 层面对批流模式已经做到统一。对于 Flink SQL,在 1.10 这个版本里面,已经可以实现完整的 DDL 功能,兼容 Hive 生态系统并且支持 Python UDF。总的来说就是:
- Flink SQL 在批模式下经过多方验证已经达到生产可用的状态。
- Flink SQL 可以在Hive 生态上直接运行,没有迁移成本。
- Flink SQL 可以做到批流在SQL 优化、算子层以及分布式运行层的一体化。
跑 TPC-DS benchmark,Flink 1.10 比 Hive-3.0 快 7 倍?
在 AI 部分,2019 Flink 重点主要在优化和铺垫 AI 的基础设施部分:
- Flink 1.9 发布一套标准化的 Machine Learning Pipeline API(这个 pipeline 的概念最早在 Scikit-learn 中提出,在其他生态中也有广泛的采纳)。AI 的开发人员可以使用这套 API(Transformer,Estimator,Model)来实现机器学习算法。
- 更好的支持 Python 生态。Flink 1.10 在 Table API 中可以支持 Python UDF,复用了 Beam 的 Python 框架来进行 Java 和 Python 进程之间的通讯。
- Alink 开源发布。Alink 是基于 Flink 的机器学习算法库,最大的亮点是对流式和在线学习的支持。
在 AI 部分还有一个很值得期待的项目是Flink AI 明年的一个重点投入方向:AI Flow。AI Flow 为 AI 链路定制了一套完整的解决方案:包括从 data acquisition,preprocessing,到 model training & validation & serving 以及 inference 的一整套链路。这个方案是针对解决现在 AI 链路里面数据预处理复杂,离线训练和在线预测脱钩等问题定制的
另一个重要方向就是对云原生生态的支持,即与Kubernetes 生态的深度融合。Kubernetes 环境可以在 multi-user 的场景下提供更好的隔离,对 Flink 在生产的稳定性方面会有所提升。Kubernetes 广泛应用在各种在线业务上,Flink 与 Kubernetes 的深度融合可以在更大范围内统一管理运维资源。
3. Reliable Streaming Infrastructure for the Enterprise
第三个议题是由戴尔科技集团带来的流式存储议: Pravega,他们的主要观点是随着流式计算在大企业用户中越来越广泛的应用,流式计算对存储也产生了新的需求:“计算是原生的流计算,而存储却不是原生的流存储” 。Pravega 团队重新思考了这一基本的数据处理和存储规则,为这一场景重新设计了一种新的存储类型,即原生的流存储,命名为”Pravega”,取梵语中“Good Speed”之意。
该项目为开源项目,想了解具体实现可查看 https://github.com/pravega/pravega/
关于Pravega我查了一些资料,印象比较深的一点是:Pravega能够应对瞬时的数据洪峰,做到“削峰填谷”,让系统自动地伴随数据到达速率的变化而伸缩,既能够在数据峰值时进行扩容提升瞬时处理能力,又能在数据谷值时进行缩容节省运行成本,而读写客户端无需额外进行调整。这一特性对于企业特别是云端业务尤为重要。Kafka和bigpipe都是需要手动扩缩容的。
Pravega 是从存储的视角来看待流数据,而 Kafka 本身的定位是消息系统而不是存储系统,它是从消息的视角来看待流数据。消息系统与存储系统的定位是不同的,简单来说,消息系统是消息的传输系统,关注的是数据传输与生产消费的过程。Pravega 的定位就是企业级的分布式流存储产品,除了满足流的属性之外,还需要满足数据存储的持久化、安全、可靠性、一致性、隔离等属性,关注数据的生产、传输、存放、访问等整个数据的生命周期。
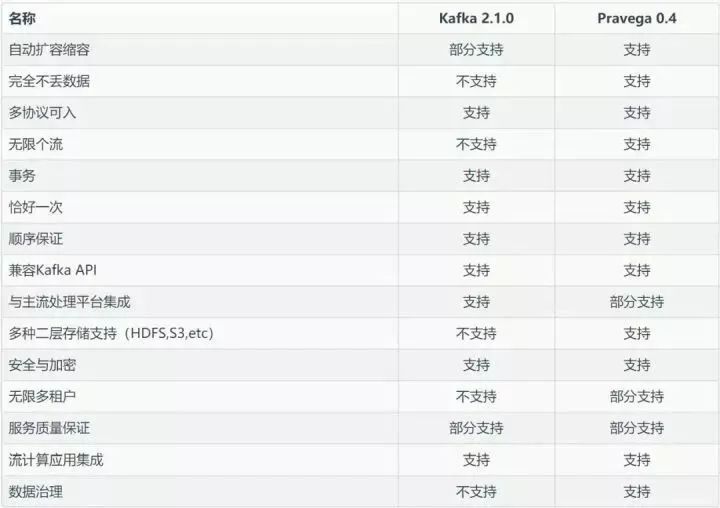
参考:
- https://www.zhihu.com/question/310212569/answer/581672480
- https://www.infoq.cn/article/MHrhw6x5qK_owazEhEw8
- https://zhuanlan.zhihu.com/p/61167127
- http://pravega.io/docs/latest/pravega-concepts/
4. Lyft 基于Apache Flink的大规模准实时数据分析平台
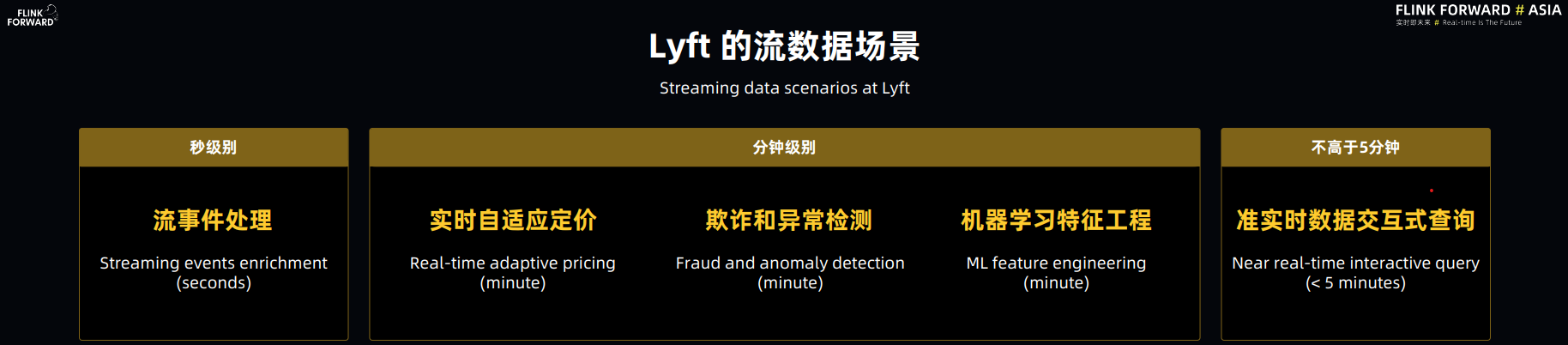
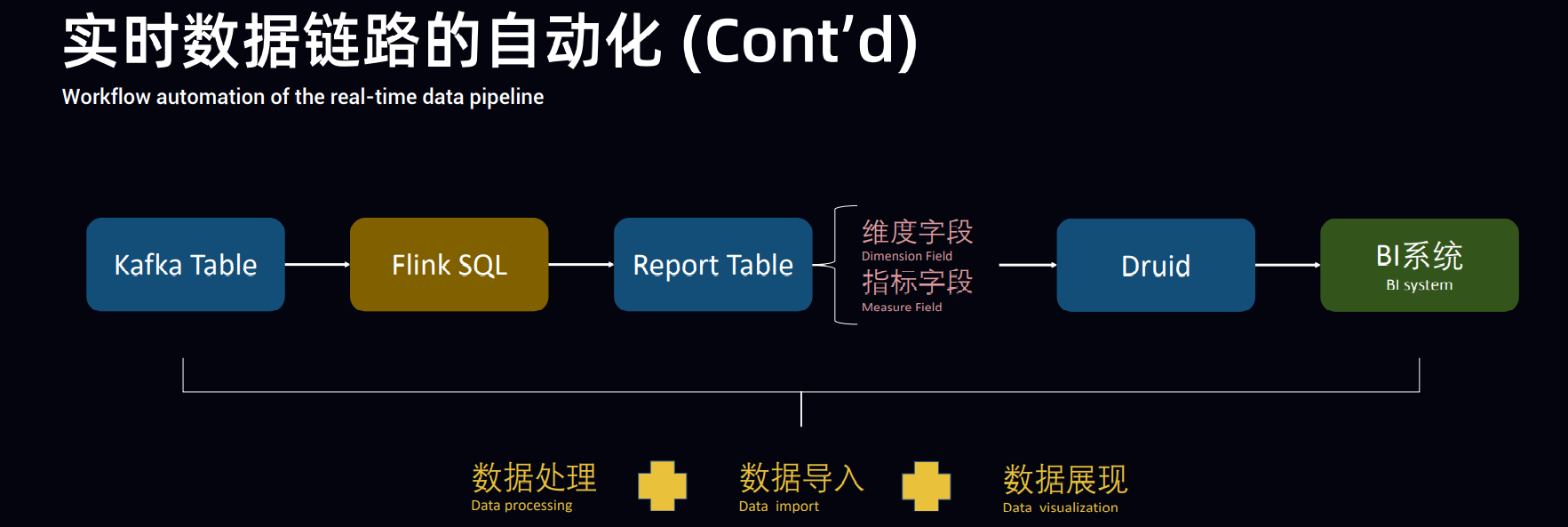
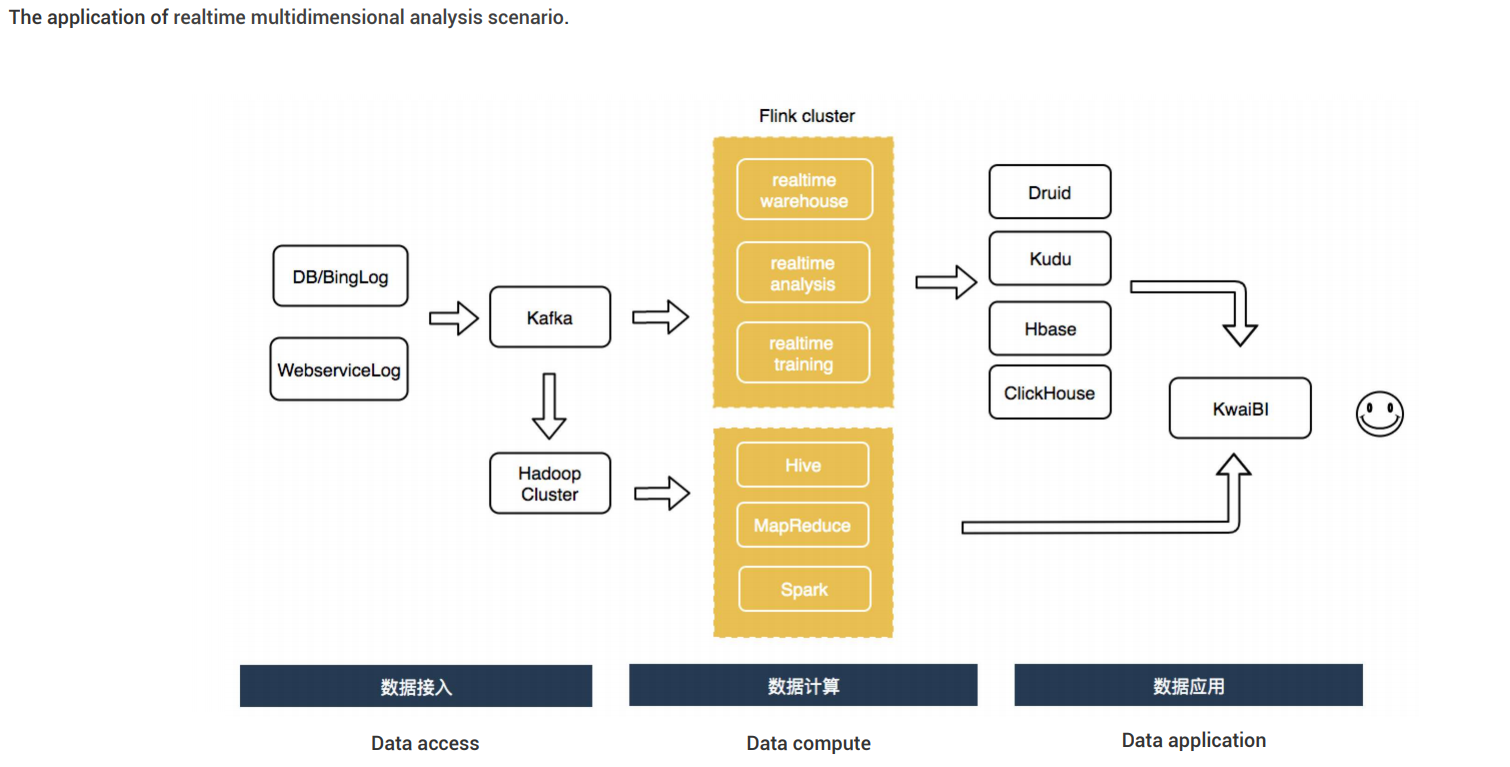
主议题的最后一场是 Flink 实践,是由 Lyft 带来的大规模准实时数据分析平台的分享。这里所说的准实时,指端到端数据延迟不超过 5 分钟,在 Lyft 内部主要用于数据交互式查询。Lyft主要有以下流数据场景:
下图是 Lyft 准实时平台架构图: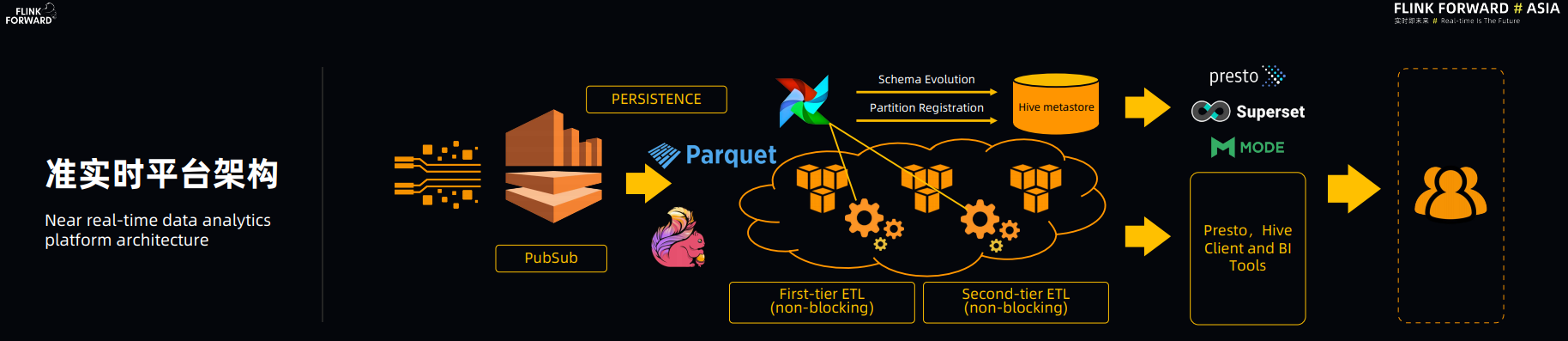
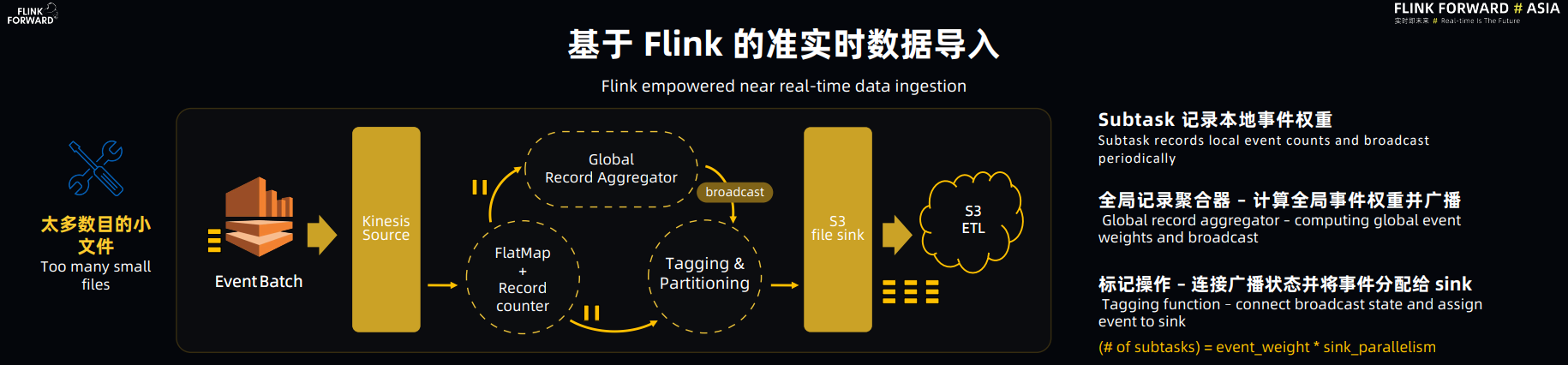
Flink 在整个架构中是用来做流数据注入的,Flink 向 AWS S3 以 Parquet 的格式持久化数据,并以这些原始数据为基础,进行多级 non-blocking 的ETL 加工(压缩去重),建立实时数仓,用于交互式数据查询。
在这个分享中印象深刻的几点:
(1) Flink 的高效性。据 Lyft 的大佬讲,这个新的平台相较于先前基于 Kinesis Client 的 ingestion 相比较,仅数据注入部分的集群就缩减了 10%,所以他们对 Flink 的高效性是非常认可的。
(2) Lyft 也提到,他们花了蛮多精力基于 Flink 的 StreamingFileSink 来解决 Flink 和 ETL 之间 watermark 的同步问题。其实我很希望他们能分享一下为何压缩去重(ETL)部分不也用 Flink 来做。如果是技术上的问题可以帮助 Flink 更好的完善自己。
(3) Lyft 提到 Flink 的重启和部署会对 SLO 造成延迟影响,subtask 停滞会造成整个 pipeline 的停滞以及期望 Flink 能够有一套在 Kubernetes 环境下运行的方案。其实这里提到的几点也在其他的几场企业实践分享中被提到,这些也是当前 Flink 亟待解决的几大痛点。
【关于Flink在failover后的拉起和恢复开销太大的问题,好几个公司都提到了,dstream3/streaming-framework比flink做的要好,可以原地拉起和恢复,而无需从源端进行数据回灌】
分会场
【实时数仓】
1. 美团点评基于 Apache Flink 的实时数仓平台实践
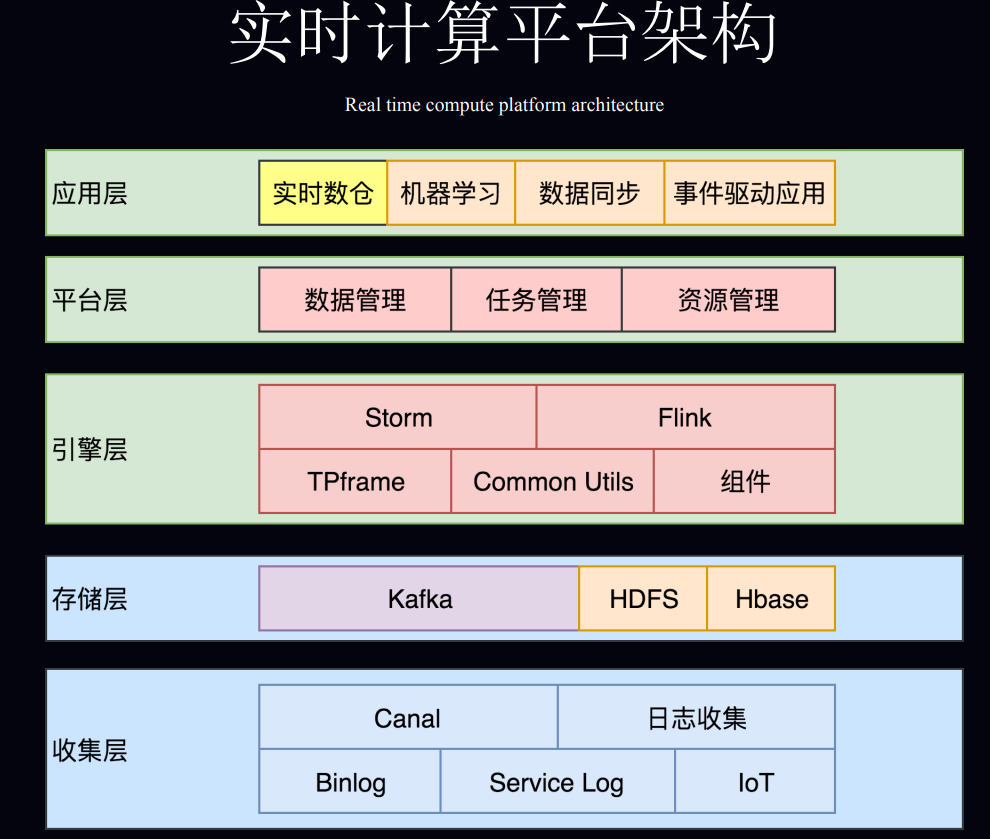
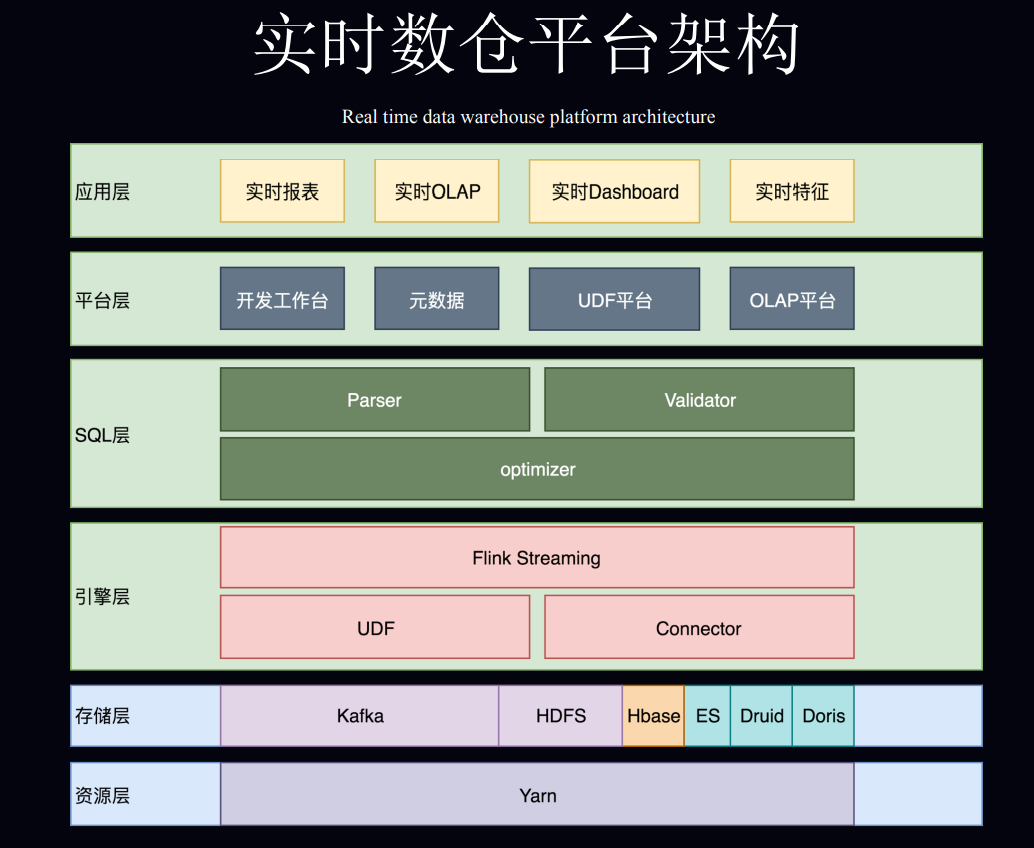
2. 小米流式平台架构演进与实践
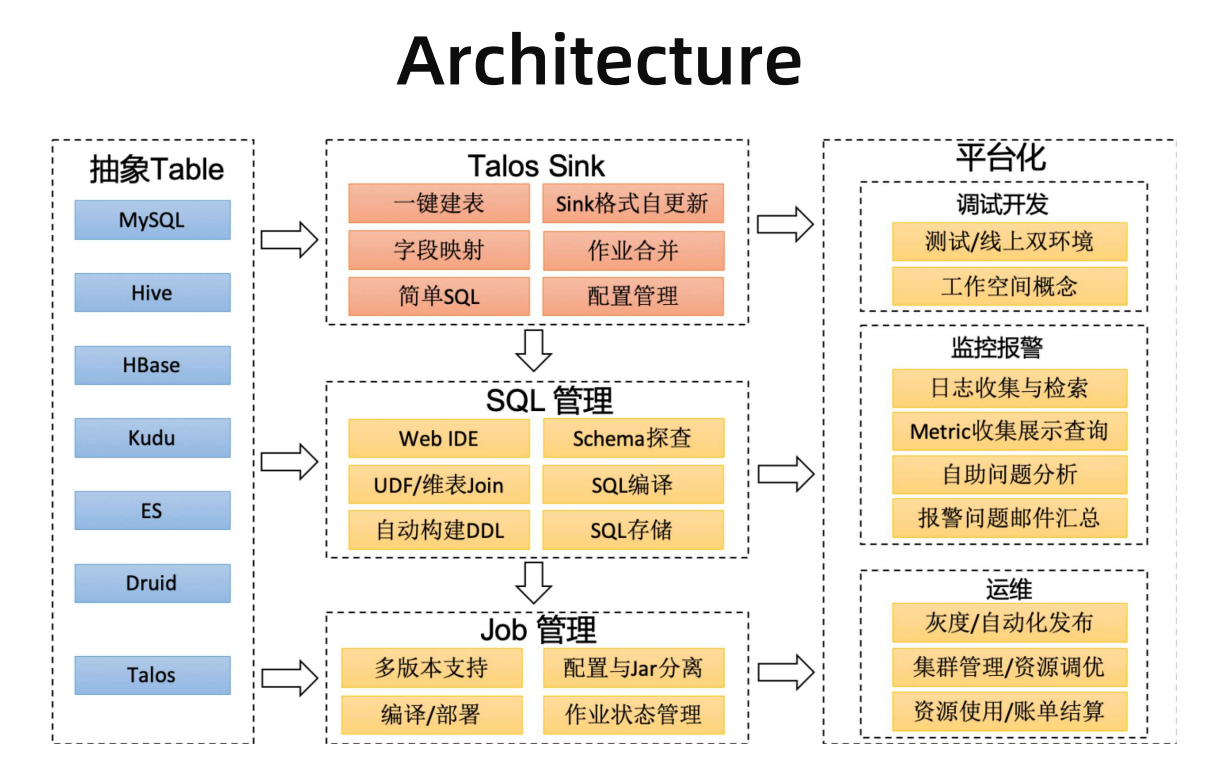
3. OPPO 基于 Apache Flink 的实时数仓实践
从传统的hdfs->hive模式转化为kafka->flink模式
4.趣头条基于 Apache Flink+ClickHouse 构建实时数据分析平台
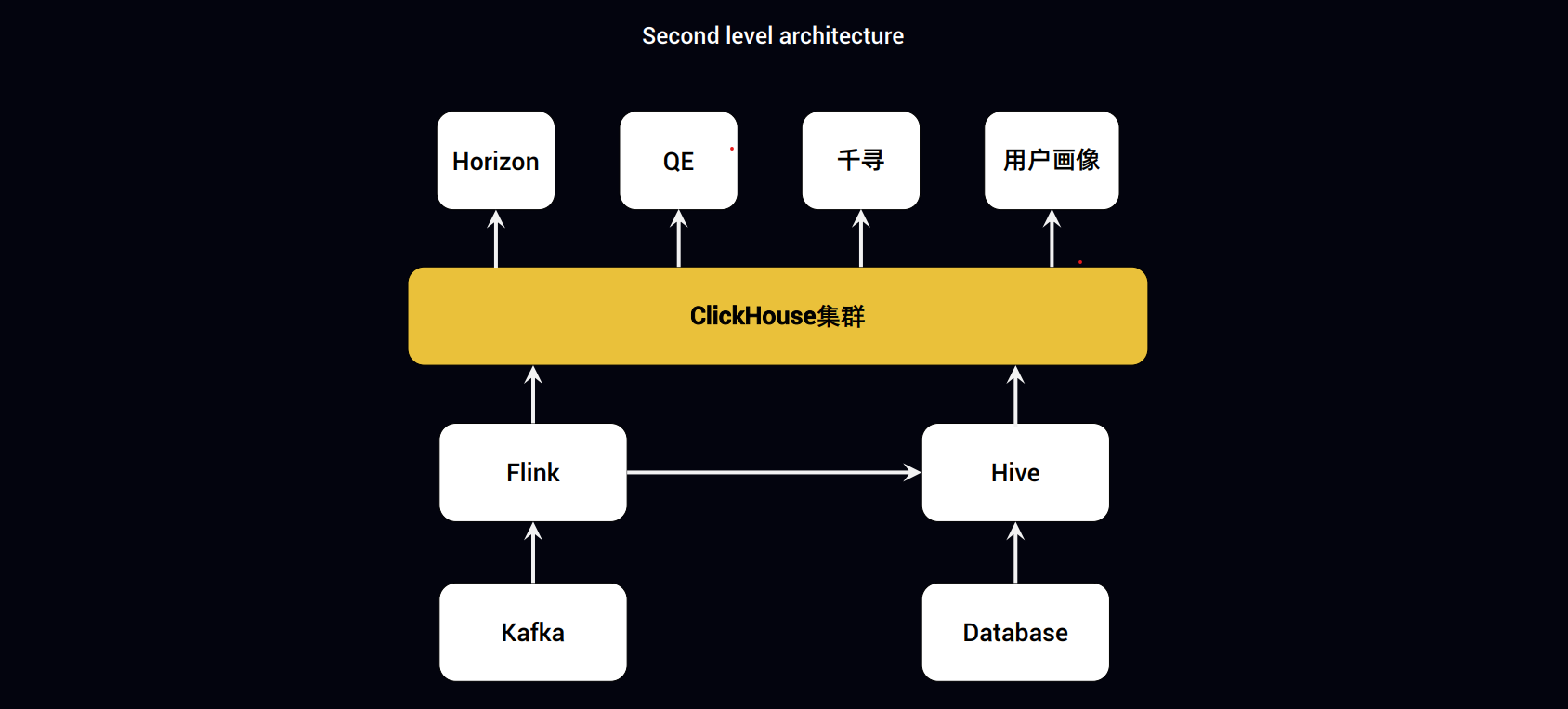
(1)一条流读取Kafka直接写入ClickHouse
(2)一条流读取Kafka写入Hive,由hive写小时级表?
(3)离线数据则由hive直接导入ClickHouse
【企业实践】
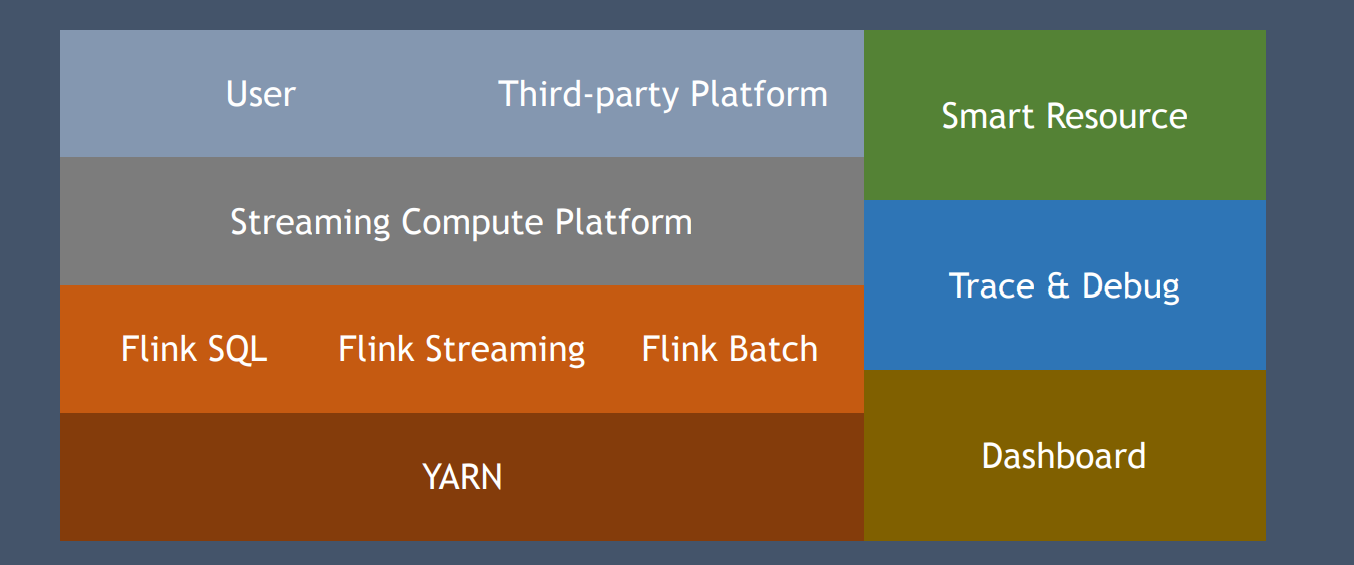
1.Apache Flink 在字节跳动的实践与优化
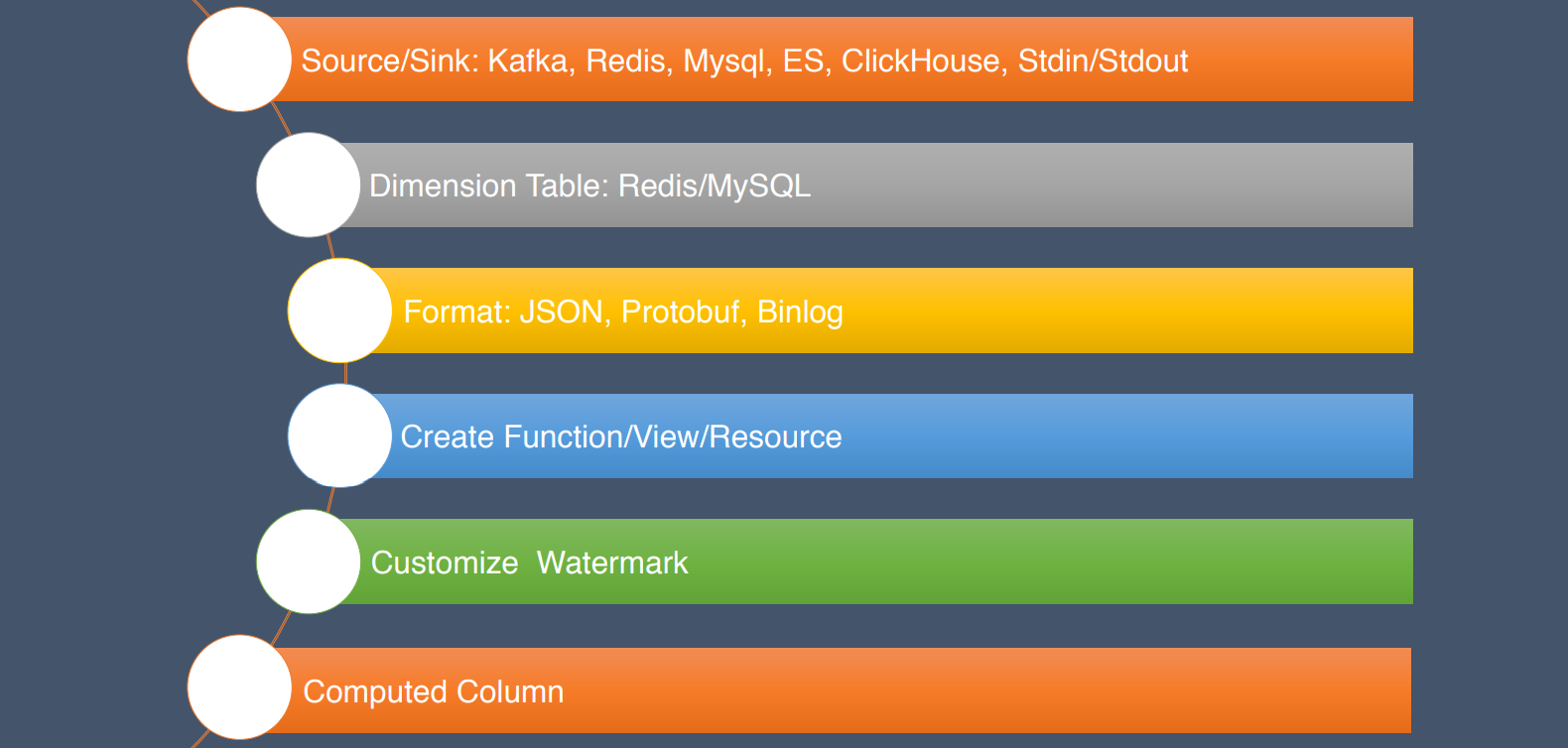
2.Apache Flink在快手实时多维分析场景的应用
3.bilibili 实时平台的架构与实践
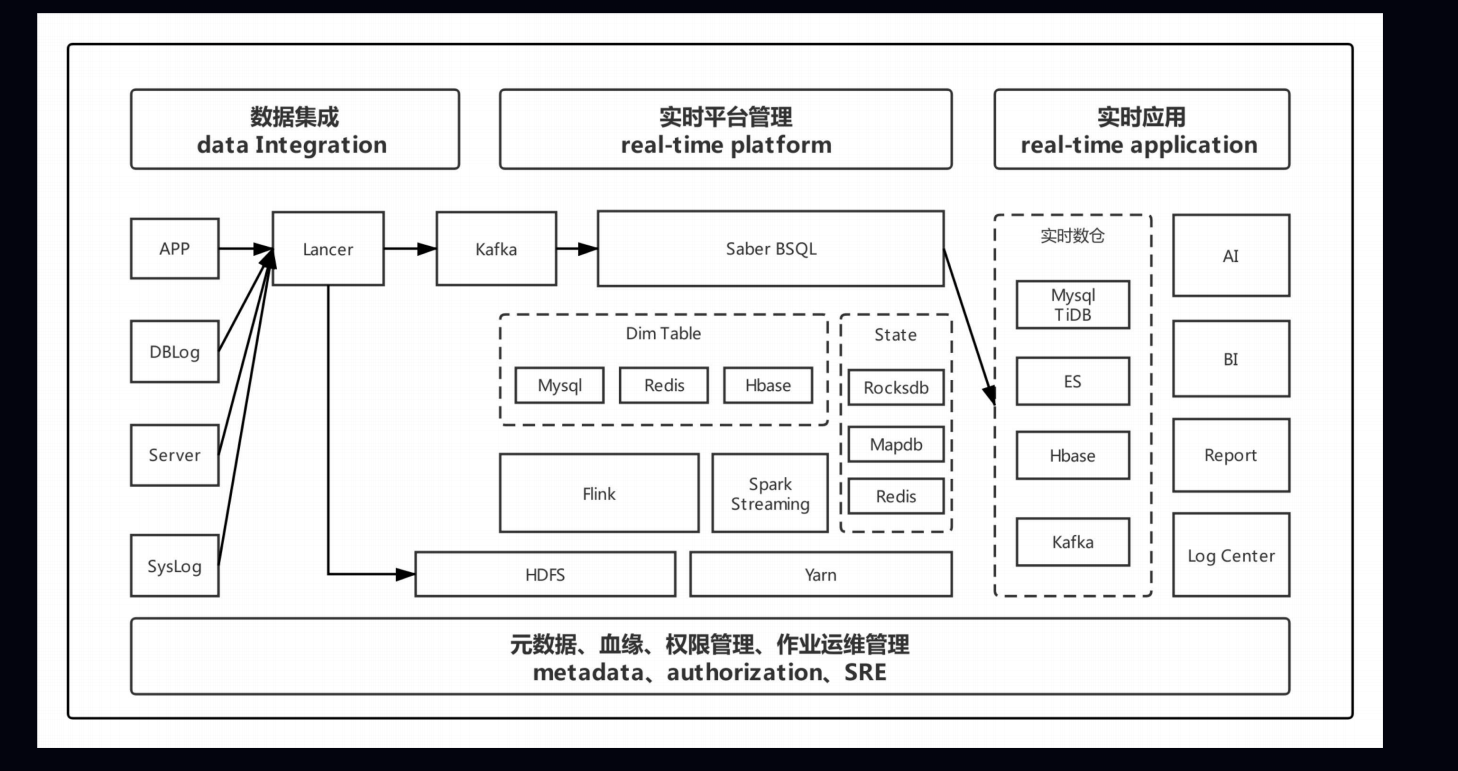
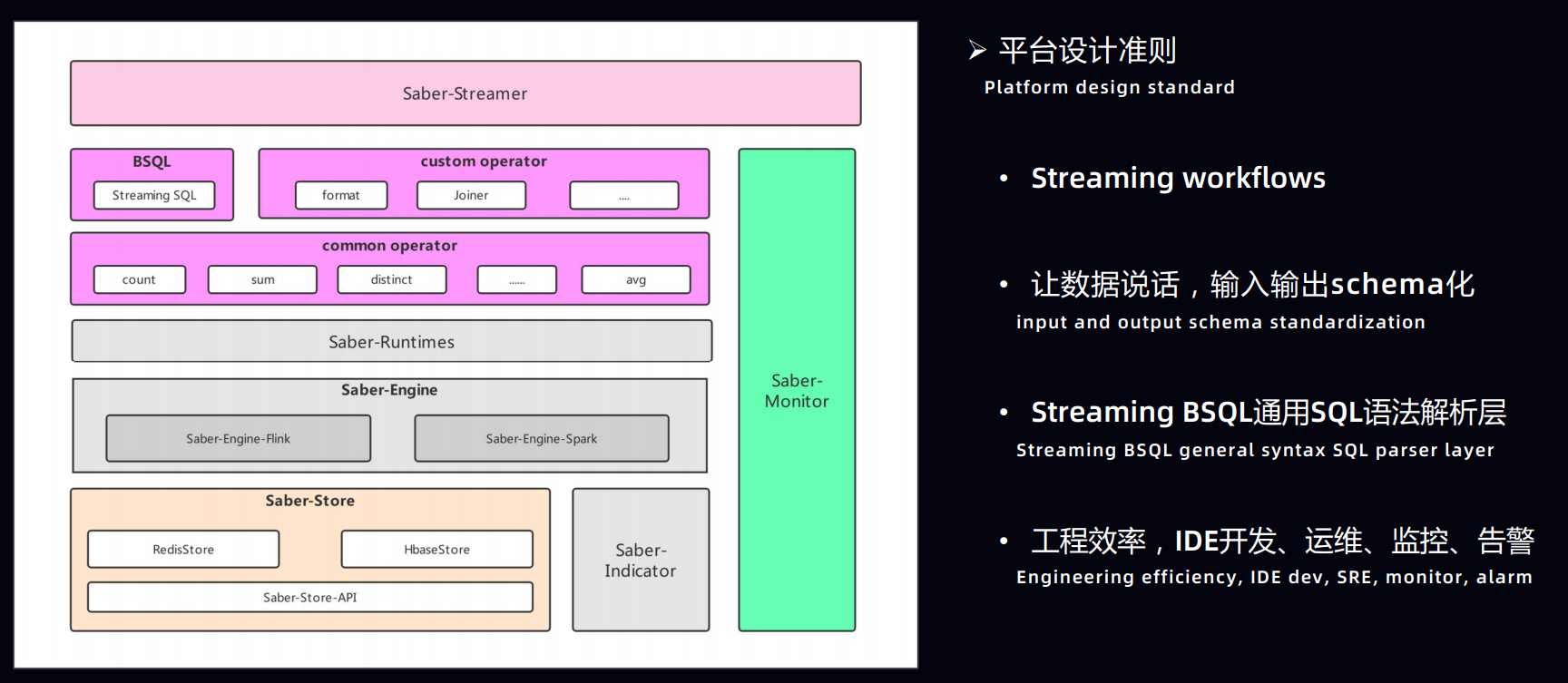
4.基于 Apache Flink 的爱奇艺实时计算平台建设实践
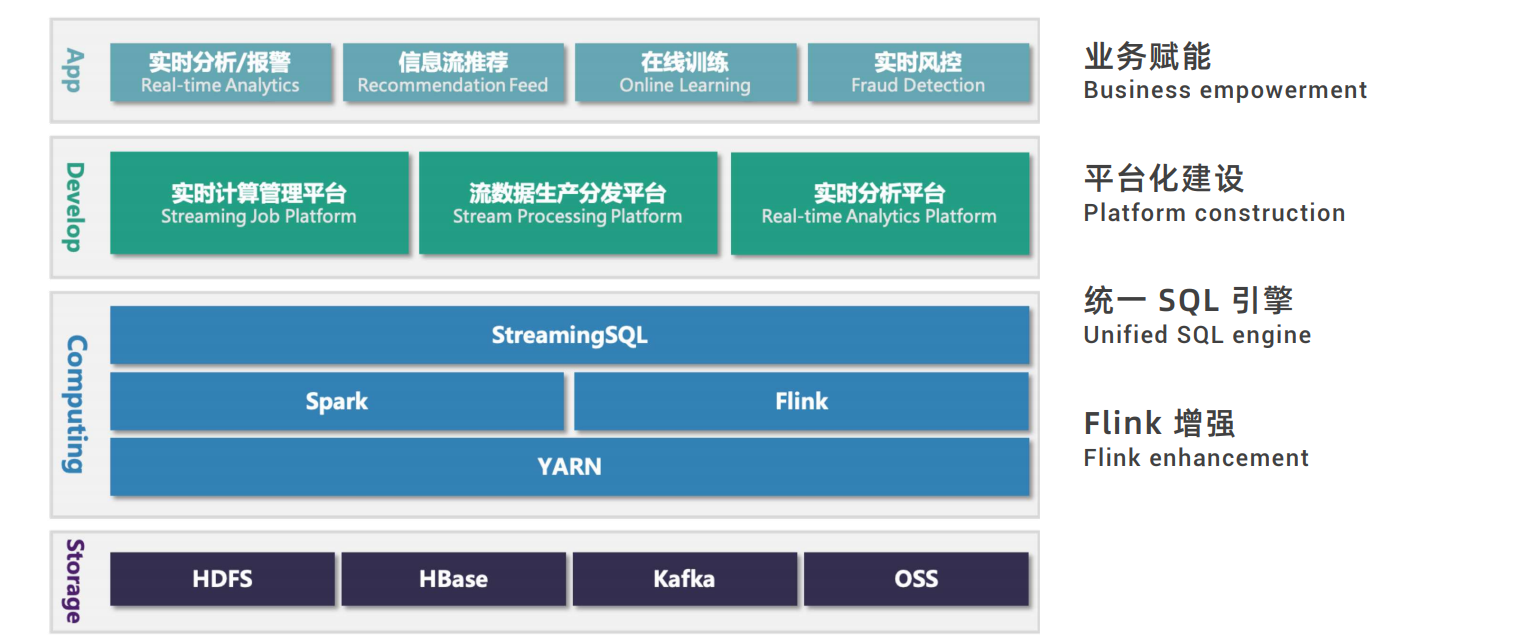
小结
| 数据源 | 计算引擎 | 存储引擎 | 调度引擎 | 查询引擎 |
|---|---|---|---|---|
| Kafka | Spark | HBase | yarn | Hive |
| Database | Flink | RocksDB | k8s | flink-sql |
| File | Hadoop | HDFS | … | my-sql |
| … | ES … | … |
相关链接
主会场视频:https://developer.aliyun.com/live/1657
ppt下载:https://ververica.cn/developers/flink-forward-asia-2019/
流控-背压
流控
流式计算系统中,任何中间节点的拥堵都可能会导致丢数据或系统雪崩,尤其是设计不够好的系统。设想这样一种数据流场景,A->B->C,B所依赖的外部存储挂了(redis/leveldb/rocksdb/hdfs)等,A->B层开始堆积数据,上下游以rpc+内存的方式传输,计算集群可能会大批量的OOM,最终导致整个系统雪崩。
流控(Flow Control),顾名思义,即流量控制,常见的思路有以下几种?
- 背压(Backpressure),就是消费者需要多少,生产者就生产多少。这有点类似于TCP里的流量控制,接收方根据自己的接收窗口的情况来控制接收速率,并通过反向的ACK包来控制发送方的发送速率。这种方案只对于cold Observable有效。cold Observable是那些允许降低速率的发送源,比如两台机器传一个文件,速率可大可小,即使降低到每秒几个字节,只要时间足够长,还是能够完成的。相反的例子就是音视频直播,速率低于某个值整个功能就没法用了(这种类似于hot Observable)。
- 节流(Throttling),说白了就是丢弃。消费不过来,就处理其中一部分,剩下的丢弃。至于处理哪些和丢弃哪些,就有不同的策略,也就是sample (or throttleLast)、throttleFirst、debounce (or throttleWithTimeout)这三种。还是举音视频直播的例子,在下游处理不过来的时候,就需要丢弃数据包。
- 打包(buffer和window),buffer和window基本一样,只是输出格式不太一样。它们是把上游多个小包裹打成大包裹,分发到下游。这样下游需要处理的包裹的个数就减少了。
- 是一种特殊情况,阻塞住整个调用链(Callstack blocking)。之所以说这是一种特殊情况,是因为这种方式只适用于整个调用链都在一个线程上同步执行,这要求中间的各个operator都不能启动新的线程。在平常使用中这种应该是比较少见的,因为我们经常使用subscribeOn或observeOn来切换执行线程,而且有些复杂的operator本身也会内部启动新的线程来处理。另外,如果真的出现了完全同步的调用链,前面的1、2、3仍然有可能适用的,只不过这种阻塞的方式更简单,不需要额外的支持。
下面简单介绍一下几种常见的流式系统中的背压机制。
Storm
对于开启了acker机制的Storm程序,可以通过设置conf.setMaxSpoutPending参数来实现反压效果,如果下游组件(bolt)处理速度跟不上导致spout发送的tuple没有及时确认的数超过了参数设定的值,spout会停止发送数据,这种方式的缺点是很难调优conf.setMaxSpoutPending参数的设置以达到最好的反压效果,设小了会导致吞吐上不去,设大了会导致worker OOM;有震荡,数据流会处于一个颠簸状态,效果不如逐级反压;另外对于关闭acker机制的程序无效.
Heron(新版storm)自动反压机制(Automatic Back Pressure)通过监控Bolt中的接收队列的负载情况,如果超过高水位就会将反压信息写入zk,zk上的watch就会通知该拓扑的所有worker进入反压,最后Spout停止发送数据,直到接收队列的负载降到低水位以下。这种方式存在的问题就是, 当下游出现阻塞时, 上游停止发送, 下游消除阻塞后,上游又开闸放水,过了一会儿,下游又阻塞,上游又限流, 如此反复, 整个数据流一直处在一个颠簸状态。具体实现:JIRA STORM-886
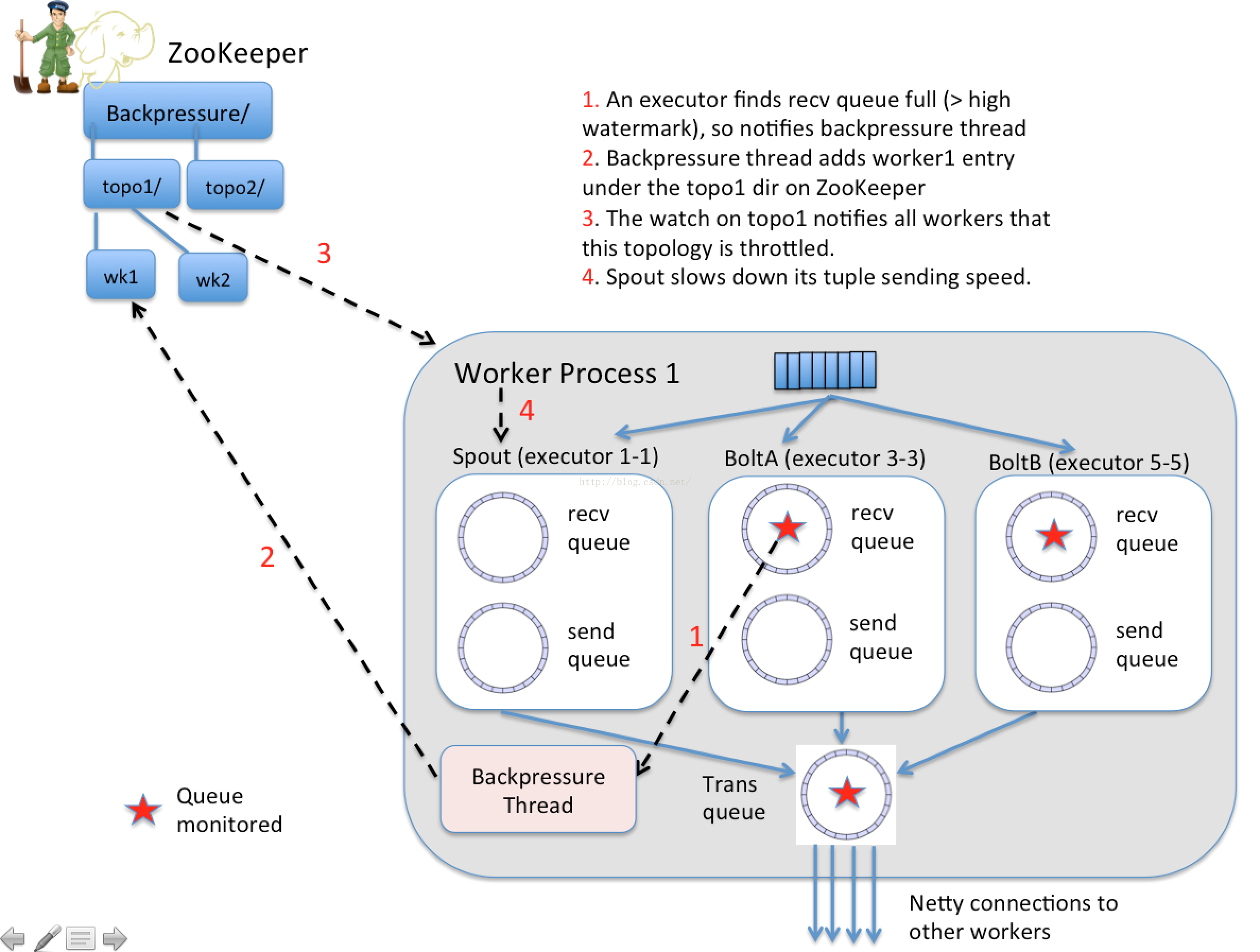
Jstorm的改进方案是逐级降速与放水来进行反压;另外,Jstorm没有引入zk,而是通过TopologyMaster来协调拓扑进行反压。
Spark Streaming
Spark Streaming程序中当计算过程中出现batch processing time > batch interval的情况时,(其中batch processing time为实际计算一个批次花费时间,batch interval为Streaming应用设置的批处理间隔),意味着处理数据的速度小于接收数据的速度,如果这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟),可以通过设置参数spark.streaming.receiver.maxRate来限制Receiver的数据接收速率,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。为了更好的协调数据接收速率与资源处理能力,Spark Streaming 从v1.5开始引入反压机制(back-pressure),通过动态控制数据接收速率来适配集群数据处理能力.
Spark Streaming Backpressure: 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。通过属性”spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
Spark Streaming的执行流程如下图所示: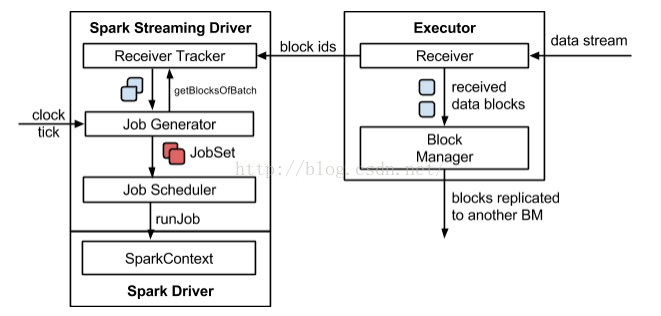
其背压流程如下:在原架构的基础上加上一个新的组件RateController,这个组件负责监听“OnBatchCompleted”事件,然后从中抽取processingDelay 及schedulingDelay信息. Estimator依据这些信息估算出最大处理速度(rate),最后由基于Receiver的Input Stream将rate通过ReceiverTracker与ReceiverSupervisorImpl转发给BlockGenerator(继承自RateLimiter).
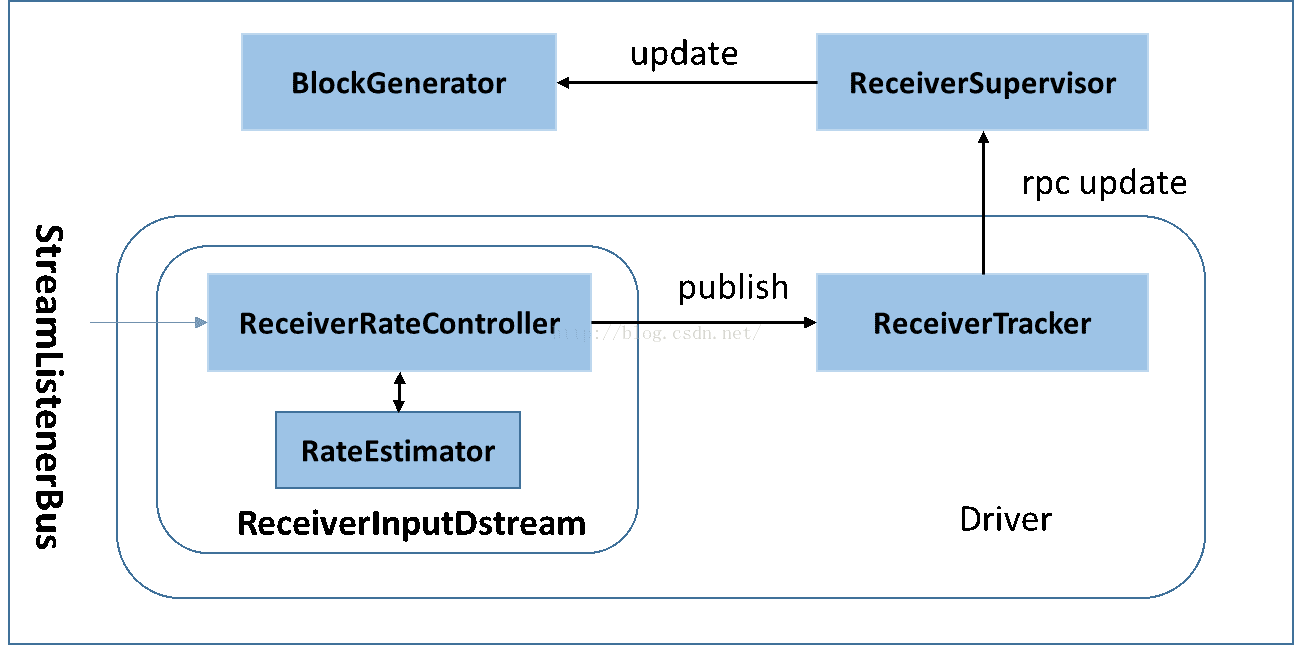
Flink
内存模型
Flink运行时的构造部件是operators以及streams。每一个operator消费一个中间/过渡状态的流,对它们进行转换,然后生产一个新的流。两个相邻的operator之间使用有效的分布式阻塞队列来作为有界的缓冲区。如同Java里通用的阻塞队列跟处理线程进行连接一样,一旦队列达到容量上限,一个相对较慢的接受者将拖慢发送者。在Flink中这些分布式的队列被认为是逻辑流,而它们的有界容量可以通过每一个生产、消费流管理的缓冲池获得。缓冲池是缓冲区的集合,它们都可以在被消费完之后循环利用。这个观点很好理解:你从池里获取一个缓冲区,填进数据,然后在数据被消费后,将该缓冲区返还回缓冲池,之后你还可以再次使用它。
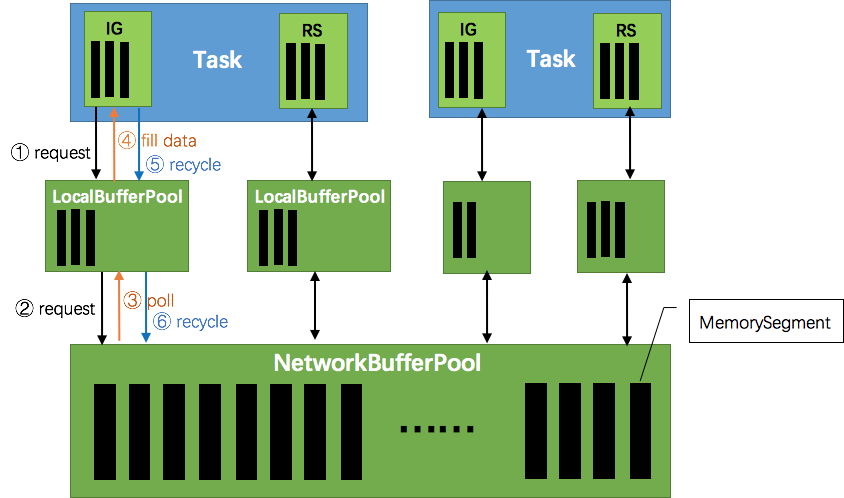
这些缓冲池的大小在运行时能动态变化。在不同的发送者/接收者存在不同的处理速度的情况下,网络栈里的内存缓冲区的数量(等于队列的容量)决定了系统能够提供的缓冲区的数量。Flink保证总是有足够的缓冲区提供给应用程序,但处理的速度是由用户的程序以及可用内存的数量决定的。内存越多,意味着系统可以轻松应对一定的瞬时背压(short periods,short GC)。越少的内存意味着需要对背压进行更多的“即时”响应(意思是,如果内存少缓冲区就容易被填满,那么需要立即作出响应,消费走数据才能应对这个问题)。
背压示例
下面这张图简单展示了两个 Task 之间的数据传输以及 Flink 如何感知到反压的:
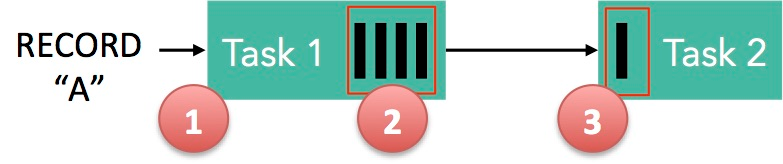
- 记录“A”进入了 Flink 并且被 Task 1 处理。(这里省略了 Netty 接收、反序列化等过程)
- 记录被序列化到 buffer 中。
- 该 buffer 被发送到 Task 2,然后 Task 2 从这个 buffer 中读出记录
结合上面两张图看:Task 1 在输出端有一个相关联的 LocalBufferPool(称缓冲池1),Task 2 在输入端也有一个相关联的 LocalBufferPool(称缓冲池2)。如果缓冲池1中有空闲可用的 buffer 来序列化记录 “A”,我们就序列化并发送该 buffer。
这里我们需要注意两个场景:
本地传输:如果 Task 1 和 Task 2 运行在同一个 worker 节点(TaskManager),该 buffer 可以直接交给下一个 Task。一旦 Task 2 消费了该 buffer,则该 buffer 会被缓冲池1回收。如果 Task 2 的速度比 1 慢,那么 buffer 回收的速度就会赶不上 Task 1 取 buffer 的速度,导致缓冲池1无可用的 buffer,Task 1 等待在可用的 buffer 上。最终形成 Task 1 的降速。
远程传输:如果 Task 1 和 Task 2 运行在不同的 worker 节点上,那么 buffer 会在发送到网络(TCP Channel)后被回收。在接收端,会从 LocalBufferPool 中申请 buffer,然后拷贝网络中的数据到 buffer 中。如果没有可用的 buffer,会停止从 TCP 连接中读取数据。在输出端,通过 Netty 的水位值机制来保证不往网络中写入太多数据(后面会说)。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数据(由于接收端缓冲池没有可用 buffer),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。另外,这会使得发送端的缓冲池得不到回收,writer 阻塞在向 LocalBufferPool 请求 buffer,阻塞了 writer 往 ResultSubPartition 写数据。
这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快于消费的速度。我们上面描述的这个方案可以从两个Task之间的数据传输自然地扩展到更复杂的 pipeline 中,保证背压机制可以扩散到整个pipeline。
总结
相较于Storm和Spark-Streaming通过监控上下游算子的处理速度以及数据堆积情况来进行背压,Flink的背压机制则更加自然简洁,无需增加额外的监控组件,也无需Zookeeper/TopologyMaster的参与,对于流量的控制和恢复响应更迅速。类似木桶原理,Flink所获得的最大吞吐量由其pipeline中最慢的operator决定。
Refer
https://www.zhihu.com/question/49618581
https://blog.csdn.net/yanghua_kobe/article/details/51214097
http://blog.csdn.net/cm_chenmin/article/details/52936575
http://wuchong.me/blog/2016/04/26/flink-internals-how-to-handle-backpressure/
Flink 调研
架构
Flink集群启动后的架构如下图所示: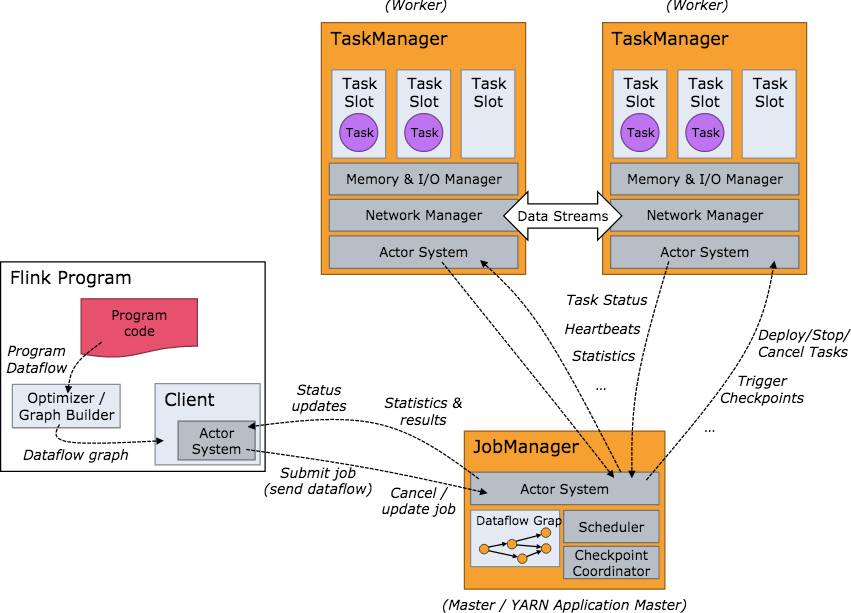
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,即一个线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
可以看到 Flink 的任务调度是多线程模型,并且不同Job/Task混合在一个 TaskManager 进程中。虽然这种方式可以有效提高 CPU 利用率,但是缺乏资源隔离机制,同时也不方便调试。类似 Storm 的进程模型,一个JVM 中只跑该 Job 的 Tasks 实际应用中更为合理。
内存管理
如今,大数据领域的开源框架(Hadoop,Spark,Storm)都使用的 JVM,当然也包括 Flink。基于 JVM 的数据分析引擎都需要面对将大量数据存到内存中,这就不得不面对 JVM 存在的几个问题:
Java 对象存储密度低。一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个bit(1/8字节)就够了。
Full GC 会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC 会达到秒级甚至分钟级。
OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
所以目前,越来越多的大数据项目开始自己管理JVM内存了,像 Spark、Flink、HBase,为的就是获得像 C 一样的性能以及避免 OOM 的发生。本文将会讨论 Flink 是如何解决上面的问题的,主要内容包括内存管理、定制的序列化工具、缓存友好的数据结构和算法、堆外内存、JIT编译优化等。
容错机制
refer: https://www.iteblog.com/archives/1987.html
Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。
容错机制通过持续创建分布式数据流的快照来实现。对于状态占用空间小的流应用,这些快照非常轻量,可以高频率创建而对性能影响很小。流计算应用的状态保存在一个可配置的环境,如:master 节点或者 HDFS上。
在遇到程序故障时(如机器、网络、软件等故障),Flink 停止分布式数据流。系统重启所有 operator ,重置其到最近成功的 checkpoint。输入重置到相应的状态快照位置。保证被重启的并行数据流中处理的任何一个 record 都不是 checkpoint 状态之前的一部分。
注意:为了容错机制生效,数据源(例如 消息队列 或者 broker)需要能重放数据流。Apache Kafka 有这个特性,Flink 中 Kafka 的 connector 利用了这个功能。由于 Flink 的 checkpoint 是通过分布式快照实现的,接下来我们将 snapshot 和 checkpoint 这两个词交替使用。
Window机制
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
窗口可以是时间驱动的(例如30s为一个时间窗口),也可以是数据驱动的(例如100个元素为一个窗口)。一种经典的窗口分类可以分成:翻滚窗口(Tumbling Window/Fixed Window,无重叠),滑动窗口(Sliding Window,有重叠),和会话窗口(Session Window,活动间隙)。Flink提供了Tumbling Time Window, Sliding Time Window, Tumbling Count Window, Session Window。
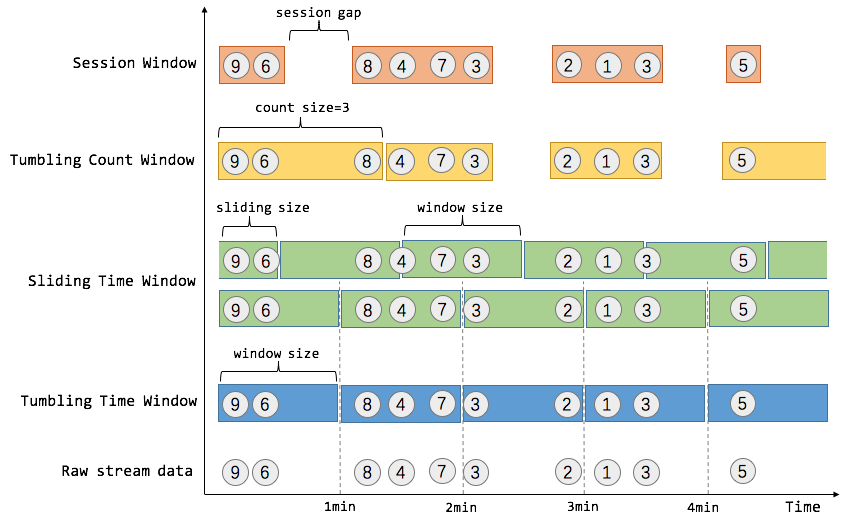
1. Time Window
Flink中主要涉及三种时间概念,event time(事件发生的时间), ingestion time(事件进入流处理系统的时间),processing time(消息被处理的时间)。窗口机制与时间类型完全解耦,即当需要改变时间类型时,不需要更改窗口逻辑。
Tumbling Time Window 例如,我们需要统计每一分钟中用户进行搜索的次数,需要将用户的行为事件按每一分钟进行切分,这样切分出来的窗口就是翻滚窗口/固定窗口。翻滚窗口能将数据流切分成不重叠的窗口,每个事件只能属于一个窗口。
Sliding Time Window 对于某些应用,他们需要平滑地进行窗口聚合。例如,我们可以每30秒计算一次最近一分钟用户可以购买的商品总数。这种窗口我们称为滑动窗口。在滑动窗口中,一个元素可以对应多个窗口。
2. Count Window
Tumbling Count Window 如果想对每100个用户的搜索行为统计总数,那么每当窗口中填满100个元素,就对窗口进行计算,这种窗口我们称之为翻滚计数窗口。
Sliding Count Window 如果想进行更平滑的聚合,每10个元素计算一次最近100个元素的搜索总数,这种窗口就是滑动计数窗口。
3. Session Window
在用户交互事件流中,我们首先想到的是将事件聚合到会话窗口中(一段用户持续活跃的周期),由非活跃的间隙分隔开。如下图所示,就是需要计算每个用户在活跃期间总共搜索的记录数,如果用户30秒没有活动则视为会话断开(假设raw data stream是单个用户的搜索行为流)。

对于session window来说,我们需要窗口变得更灵活。基本的思想是这样的:SessionWindows assigner 会为每个进入的元素分配一个窗口,该窗口以元素的时间戳作为起始点,时间戳加会话超时时间为结束点,也就是该窗口为[timestamp, timestamp+sessionGap)。比如我们现在到了两个元素,它们被分配到两个独立的窗口中,两个窗口目前不相交,如图:

当第三个元素进入时,分配到的窗口与现有的两个窗口发生了叠加,情况变成了这样:

需要注意的是,对于每一个新进入的元素,都会分配一个属于该元素的窗口,都会检查并合并现有的窗口。在触发窗口计算之前,每一次都会检查该窗口是否可以和其他窗口合并,直到trigger触发后,会将该窗口从窗口列表中移除。对于 event time 来说,窗口的触发是要等到大于窗口结束时间的 watermark 到达,当watermark没有到,窗口会一直缓存着。所以基于这种机制,可以做到对乱序消息的支持。
一般而言,window是在无限的流上定义了一个有限的元素集合。这个集合可以是基于时间的,元素个数的,时间和个数结合的,会话间隙的,或者是自定义的。Flink 的 DataStream API提供了简洁的算子来满足常用的窗口操作,同时提供了通用的窗口机制来允许用户自己定义窗口分配逻辑。
4. Window API
- Window Assigner: 用来决定某个元素被分配到哪个/哪些窗口中
- Trigger:触发器。决定一个窗口何时能够被计算或清除,每个窗口都会有一个自己的Trigger
- Evictor:在Trigger被触发后,在窗口被处理之前,Evictor(如果有Evictor的话)会用来剔除窗口中不需要的元素,相当于一个filter。
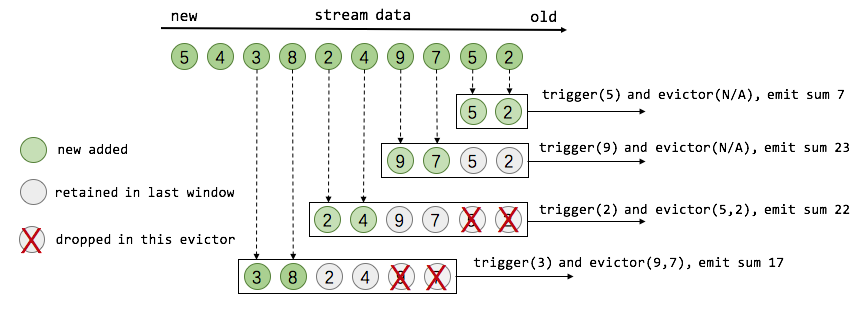
5. watermark
当operator通过基于Event Time的时间窗口来处理数据时,它必须在确定所有属于该时间窗口的消息全部流入该operator时才能开始数据处理。但是由于消息可能是乱序的,所以无法直接确认何时所有属于该时间窗口的消息全部流入此operator。Watermark就是用来支持基于Event Time的窗口计算的。
Watermark包含一个时间戳,Flink使用Watermark标记所有小于该时间戳的消息都已流入,Flink的数据源在确认所有小于某个时间戳的消息都已输出到Flink流处理系统之后,会生成一个包含该时间戳的Watermark,插入到消息流中输出到Flink流处理系统中,Flink operator按照时间窗口缓存所有流入的消息,当operator处理到Watermark时,它对所有小于该Watermark时间戳的时间窗口数据进行处理并发送到下一个operator节点,然后也将Watermark发送到下一个operator.
为了保证能够处理所有属于某个时间窗口的消息,操作符必须等到大于这个时间窗口的WaterMark之后才能开始对该时间窗口的消息进行处理,相对于基于Operator Time的时间窗口,Flink需要占用更多内存,且会直接影响消息处理的延迟时间。对此,一个可能的优化措施是,对于聚合类的操作符,可以提前对部分消息进行聚合操作,当有属于该时间窗口的新消息流入时,基于之前的部分聚合结果继续计算,这样的话,只需缓存中间计算结果即可,无需缓存该时间窗口的所有消息。
6. 窗口计算流程
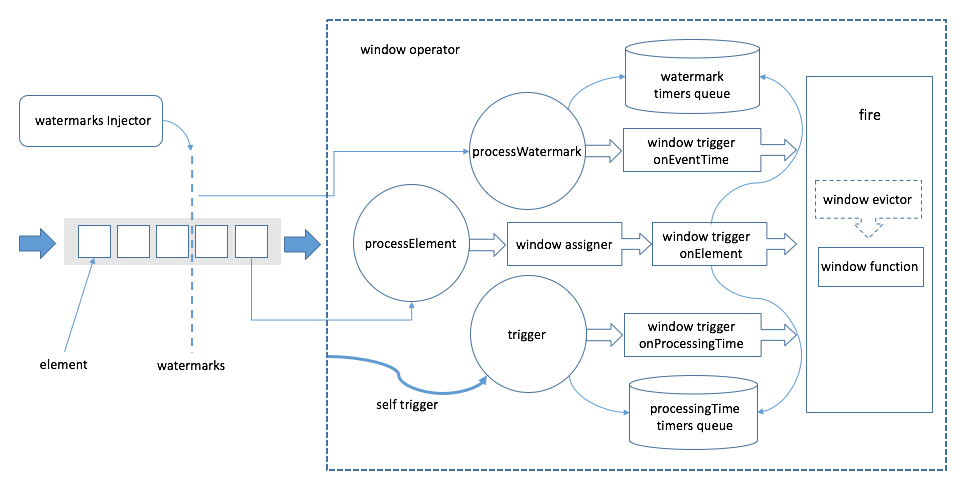
上图中,左侧从左往右为事件流的方向。方框代表事件,事件流中夹杂着的竖直虚线代表watermark,Flink通过watermark分配器(TimestampsAndPeriodicWatermarksOperator和TimestampsAndPunctuatedWatermarksOperator这两个算子)向事件流中注入watermark。元素在streaming dataflow引擎中流动到WindowOperator时,会被分为两拨,分别是普通数据和watermark。
如果是普通数据,则会调用processElement方法(上图虚线框中的三个圆圈中的一个)进行处理,在processElement方法中,首先会利用窗口分配器为当前接收到的元素分配窗口,接着会调用触发器的onElement方法进行逐元素触发。对于时间相关的触发器,通常会注册事件时间或者处理时间定时器,这些定时器会被存储在WindowOperator的处理时间定时器队列和watermark定时器队列中(见图中虚线框中上下两个圆柱体),如果触发的结果是fire,则对窗口进行计算。
如果是watermark(事件时间场景),则方法processWatermark将会被调用,它将会处理watermark定时器队列中的定时器。如果时间戳满足条件,则利用触发器的onEventTime方法进行处理。
而对于处理时间的场景,WindowOperator将自身实现为一个基于处理时间的触发器,以触发trigger方法来消费处理时间定时器队列中的定时器满足条件则会调用窗口触发器的onProcessingTime,根据触发结果判断是否对窗口进行计算。
Refer
关于watermark的提问:https://blog.csdn.net/lmalds/article/details/52704170
关于数据交换的提问:https://blog.csdn.net/yanghua_kobe/article/details/51235544
关于定时器的提问:https://blog.csdn.net/yanghua_kobe/article/details/52966156
关于滑动窗口的提问:https://blog.csdn.net/wwwxxdddx/article/details/51706900
http://wuchong.me/blog/2016/05/03/flink-internals-overview/
http://doc.flink-china.org/latest/concepts/programming-model.html
《代码整洁之道》读书笔记
[toc]
最近在阅读《Clean Code》,读书笔记记录于此。
什么样的代码是好代码?
- 好代码让人赏心悦目
- 完成功能 - 基本要求
- 划分合理 - 低耦合、高内聚
- 风格规范 - 代码易阅读、易维护
- 实现高效 - 性能好
- 简洁实用 - 避免过度设计、避免炫技
命名
- 使用读得出来的名称
- 避免过度缩写,例如genymdmhs
- 名称的长短应与其作用域大小一致
- 越是作用域大的变量的名字越应该清晰地描述其含义,便于搜索
- 避免使用编码
- 无需将类型或作用域等编码进变量名中,如 f_price, g_count, m_name…,否则变量类型修改之后,变量名也需要跟着更新,否则就会误导读者
函数
- 函数的第一规则是要短小;第二规则是还要更短小
- 最好不要超过100行,20行封顶最佳
- 避免过多嵌套:函数的缩进层级不应该多于1层或2层
- 函数应该做一件事。做好这件事。只做这一件事。
- 函数参数越少越好,应尽量避免三个及以上的参数。
- 参数数目越少,测试时需要覆盖的场景数越少,越方便测试
- 尽量避免使用参数进行信息输出,最好直接用返回值进行输出
- 有时候返回值比放在参数中多了一次拷贝??? RVO, NRVO
- 使用异常代替返回错误码 ?
- 忘了在哪本书里面看的,说C++里面尽量避免使用异常??感觉本书主要针对java编程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29try{
deletePage(page);
registry.deleteReference(page.name);
configKeys.deleteKey(page.name.makeKey());
}
catch(Exception e) {
logger.log(e.getMessage());
}
// 上述代码 错误处理与正常流程被混为一谈。。。
public void delete(Page page) {
try{
deletePageAndAllReferences(page);
}
catch(Exception e) {
logError(e);
}
}
private void deletePageAndAllReferences(Page page) throws Exception {
deletePage(page);
registry.deleteReference(page.name);
configKeys.deleteKey(page.name.makeKey());
}
private void logError(Exception e) {
logger.log(e.getMessage());
}
// 上述拆分在java中固然好。。但在C++中就不能不在每个子函数内部添加try{}catch(){throw...}
- 忘了在哪本书里面看的,说C++里面尽量避免使用异常??感觉本书主要针对java编程
- 从一开始就尽量遵照规则写好每一个函数?还是先完成功能,再打磨、重构、组装成遵循规则的函数?
注释
- 注释本身就是一种失败?是一种代码表达能力低的表现?
- 注释不能美化糟糕的代码;尽量用代码来阐述;避免不必要的注释
- 不必为了注释而注释
- 注释也会说谎,尤其当注释没能被持续维护的情况下
格式
- 纵向格式
- 不同的思路或表达之间应该用空白行区隔开
- 紧密相关的代码应该相互靠近
- 若某个函数调用了另外一个,就应该把它们放到一起,而且调用者应该尽可能放在被调用者上面。
- 横向格式
- 一行代码不要超过120个字符
- 根据运算符的优先级进行空格, e.g. a*b + c*d vs. a * b + c * d
对象和数据结构
- 对象把数据隐藏于抽象之后,曝露操作数据的接口;数据结构曝露其数据,没有提供有意义的函数。
- 过程式代码(使用数据结构)便于在不改变现有数据结构的前提下添加新函数,面向对象代码便于在不改变既有函数的前提下添加新类。过程式代码难以添加新数据结构,因为必须修改所有函数;面向对象代码难以添加新函数,因为必须修改所有类。实际使用时需要根据情况进行选择(希望灵活地添加数据类型?还是操作行为?)。
- The Law of Demeter:模块不应该了解它所操作对象的内部情形。方法不应调用由任何函数返回的对象的方法。
错误处理
- 错误处理很重要,但如果他搞乱了代码逻辑,就是错误的做法
- 可控异常违反了开放/封闭原则。如果你在方法中抛出可控异常,而catch语句在三个层级之上,你就需要在catch语句和抛出异常处之间的每个方法签名中声明该异常。这意味着对软件较低层级的修改,都将波及较高层级的签名。
- 将第三方api打包是个良好的实践手段。当你打包一个第三方api,你就降低了对它的依赖:未来你可以不太痛苦地改用其他代码库。
- 不要返回或者传递null值。返回null值,等于在给调用者添乱,试想如果有一处没有进行null检查,应用程序就会失控
- 可以抛出异常,或者返回特例
- 如果将错误处理隔离看待,独立于主要逻辑之外,就能写出鲁棒而整洁的代码。
边界
单元测试
类
201 principles of software development
软件开发中的201条原则
本文翻译自《201 principles of software development》
基本原则
- 质量第一。
- 不同的人对软件质量的定义不同。对于开发者来说,质量意味着优雅的设计和编码;对于高压环境下的用户来说,质量意味着响应时间和容量;对某些客户来说,质量意味着满足所有已知的和未知的需求…一个项目的质量取决于它需要优先考虑的事以及各参与方。
- 产量和质量不可兼得。产量越高,则质量越低。贝尔实验室发现,要想实现每千行代码只有1~2个bug,那么每人月只能产出150~300行代码。
- 高质量的软件是可以实现的。大型的软件系统是能以很高的质量构建的,但必须以很高的价格:每行代码$1000。作为开发者,要知道那些能够提高软件质量的技术:多与用户沟通,构建原型,保持设计简单,检查,雇佣最优秀的人…
- 不要试图改造软件质量。就好比不要试图把一个测试原型(throwaway prototype)转化成产品一样。
- 可靠性差比效率低更可怕。
- 尽早交付产品。可以尽快构建一个原型,让用户体验,一方面能早日收集到反馈,一方面可以验证需求,便于后续开发出令用户满意的产品。
- 与客户/用户沟通。人和环境都可能发生变化,跟进变化的唯一方法就是交流。
- 目标对齐:开发人员与客户的目标需要一致,尤其是在产品功能的优先级上。
- 先做一个测试原型(throwaway prototype), 不要试图第一次就做好一个完整的系统,尤其是面对一个新的产品和领域时。
- 13.
- 27.
- 35.
- 37.
需求分析
软件设计
- 把需求文档转变成设计文档并不是一件容易的事儿
- 跟踪每一个需求,记录每一个需求的设计及实现情况(可以用表格来记录)
- 评估每一种方案,从中选出最好的
- 没有文档的设计不算真正的设计
- 封装,便于维护以及隔离错误
- 不要重复造轮子
- KISS(Keep It Simple, Stupid)原则,即 保持简洁和单纯
- 避免过多的特殊情况:如果需要考虑的特殊情况太多,说明设计或算法有问题
- 最小化计算机世界与现实世界的距离,即 在选择模型和方法时尽可能地模拟现实世界
- 保持设计的智能可控性,本质上是倡导分层设计,并提供多种视角 (->80)
- 保持概念完整性,包括数据结构的组织、模块间的通信方式、错误警告等等的一致性。即使是由多个人开发的系统,看起来也像一个人开发的一样。
- 概念错误比语法错误更重要、更难以排查。
- 松耦合,高内聚
- 为改变而设计,即 所作的设计必须能够适应变化的需求:模块化、可移植、可扩展、贴近现实(69)、智能可控(70)、概念完整(71)
- 设计需要考虑后期维护。就可维护性而言,架构的选择比算法和代码更重要。
- 设计需要考虑错误情况。尽量做到:
有些具体方法可以帮助提高设计的鲁棒性:1. 不引入错误 2. 引入的错误很容易检测到 3. 部署后依然存在的错误要么不重要,要么能够避免执行过程中出现灾难性问题1. 不要遗漏任何一种状态,例如一个变量有4种取值,不要只检查其中的3种 2. 预测尽可能多的“impossible”的情况,并给出恢复策略 3. 为了排除引发灾难的情况,使用故障树(fault tree)分析预测不安全的情形 - 构建通用性软件。通用性强的软件/组件一般运行会稍微慢一些。
- 构建灵活性软件。灵活性强的组件一般比通用性强的组件运行更高效。
- 使用高效的算法。要求设计者了解各种算法并能够进行算法复杂度分析。
- 模块规格说明应该包含用户需要的所有信息,不要加入用户不需要的任何信息。即模块化。
- 设计是多维度的,包括 打包(packaging, what is part of what), 分层(hierarchy, who needs whom), 调用(invocation, who invokes whom), 流程(processes)…
- 伟大的设计来自于伟大的设计者
- 了解你的应用程序,例如压力环境下的预期行为、输入频率、响应时间、天气的影响…等等
- 可以复用一些模块或组件,因为复用的成本小且效率高。
- 对于软件来说”garbage in, garbage out”是不正确的。对于无效的输入,软件应该给出智能的回应,指出为什么无效;并且不应该进行处理,而是返回错误码,避免错误向后扩散。
- 可以通过冗余来实现软件可靠性:
- 并行策略,例如mr任务,每个分片的job都会起多个相同的、互不影响的task,如果其中一个跑完了,就可以kill掉其他的了
- 冷备,当主控机器出现硬件故障时,可以启动备用机器继续提供服务
软件的高可靠性需要很高的代价,有时针对一套需求可能需要提供两套设计方案。
编码原则
87. 避免花招(avoid tricks)
- 许多程序员喜欢在编码时使用一些奇淫技巧以显示他们的聪明才智,但这无疑降低了代码的可读性和可维护性
88. 避免全局变量
89. 自上而下写代码
- 人们习惯从上到下阅读代码,因此编码时要能够便于读者理解。自上而下编码包括:
1. 文件头部要添加详细的注释,以说明程序的用途和用法
2. 预先指定外部访问的程序、变量、算法
3. 采用结构化编程方法
90. 避免副作用(avoid side-effect)
- 程序的副作用是指程序基本功能之外的一些效果,且在程序外部是可见可感知的 ???副作用是软件中很多微小错误的来源,是最难发现的一类错误。
91. 使用有意义的名字
- 无意义的缩写命名,例如"N_FLT","F",看似减少了按键次数,其实是降低了开发效率:
1. 测试和维护风险增加,因为人们需要花很多时间去猜测和理解命名
2. 对于无意义的缩写,因为需要添加注释来解释命名,总的按键次数反而增加了
- 好的程序员应该只用10~15%的时间来打字(typing),其他大部分时间用来思考(thinking).
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
测试原则
管理原则
管理包含软件开发周期中的一系列活动,包括规划、控制、监督、汇报等。
127. 好的管理比好的技术更重要
1. 好的管理可以激励人们做到最好;相反,差的管理会使人们失去动力
2. 并没有普遍适用的正确的管理风格;管理风格可以因时因地因人而异,重点在于必须适应其所在的环境。
128. 采用合适的解决方法:技术问题需要技术方案,政治问题需要政治解决,管理问题需要合适的管理方法。
129. 不要对你读到的所有内容都深信不疑
1. 当一个人相信某个哲理时,他倾向于寻找能够支撑这个哲理的数据,而丢弃那些不支持该哲理的数据
2. 当你读到“你可以用方法X得到93%的提高(产量or质量)”时,这个方法或许能够达到预定的结果,但也可能存在例外。很大可能是,大部分工程都达不到如此戏剧性的结果;甚至,有些工程使用方法X后产量还降低了。
130. 理解客户的优先级
1. 你可以从需求分析中获知一些用户的优先级信息,难的是如何理解那些可能会发生变化的优先级
2. 另外,要理解用户所说的基本的(essential)、期望的(desirable)、可选的(optional)的需求。试想,如果只完成了基本需求,而没有完成任何期望的或者可选的需求,用户会满意吗?
131. 人才是成功的关键
1. 有经验、有才华的高技术人才是按时按预算完成软件的关键。正确的人选,即使在工具/语言/方法有限的情况下也能成功;而错误的人选,即使在工具等资源充足的情况下也可能失败。
2. 根据COCOMO模型,最好的人选有4倍于其他人的效率;所以及时那个人需要4倍于他人的薪水,你也没有吃亏;如果他要的更少,你不仅节约了成本还得到了好的产品。
132. 少量有技术的人比大量没有技术经验的人要好
1. 与其投入大量没有经验的工程师,不如分配给几个好的、有经验的工程师
2. 另外,为了避免几个好的工程师都离开,应该对人员配置进行适当的混合,尤其注意不要太偏向于任何一个人
133. 倾听你的队员:如果你和团队成员之间没有信任,那么你们的项目必将失败。信任的第一原则就是倾听。
134. 相信你的队员
1. 相互信任是成功的管理的基本要素。如果你相信你的队员,他们就会值得你信任;如果你表现出不信任他们,他们也会给你不信任他们的理由。信任是相互的,当你相信他们,并且让他们没有理由不相信你时,他们就会信任你。
2. 当你的一个员工跟你说:“我今天下午可以2点离开吗?本周的后面几天我会多工作几个小时补回来的”,此时你应该说“可以”。你什么都没有失去,反而赢得了员工的忠诚和尊敬。你扮演坏人的机会要远多于扮演好人的机会,因此抓住每一个可以做好人的机会。说不定哪一天,你就需要那个员工加几个小时的班以便帮忙完成任务。
135. 期望优秀和卓越
1. 当你对员工抱有很高的期望时,他们会做的更好!在很多实验中,将一群人分成两个组,给他们定下相同的目标,对第一组表现出很高的期望,同时表现出视第二组为平庸之辈,这种情况下,第一组总是会比第二组做的更好!
2. 如何表现出你对他们有很高的期望呢?你可以以身作则,树立榜样(如努力工作,不在工作期间玩游戏...);给员工提供教育福利以帮助他们取得最好的成绩;嘉奖优秀的行为;鼓励表现差的员工养成更好的习惯、作出更好的产品,即使没能引导他们做的更好,也可以帮他们寻找其他合适的机会(公司内外)。你不能允许他们一直待在不合适的岗位上,但你也要表现出同情和理解。
136. 沟通技巧很重要:招聘过程中不能低估沟通和协作的重要性
137. 帮忙打水
1. 当你的员工正在加班完成一个项目时,你应该和他们工作相同的时间。
2. 即使无法提供工程上的帮助,也要让他们知道你与他们同在:帮忙订披萨,买苏打水,带水等,一切他们需要的事情...
138. 给不同的员工以不同的激励
1. 不同的人想要的激励可能是不同的,有的想要加薪,有的想要升职,有的或许只想要一台高性能的电脑...
2. 想要发现激励每个人的因素并不是一件简单的事,一个比较好的方法就是倾听,剩下的就是去尝试。但不管怎样,都不要因为怕选择错误的激励方式而放弃提供嘉奖。
139. 保持办公环境的安静
- 高效的员工和公司都会提供安静的、私有的办公环境;与之对应的是大部分企业都是开放的景观办公室,降低了物理设备成本,说是方便沟通,但其实是方便了噪音和干扰,严重影响了生产力和质量
140. 人力和时间是不能互换的
- 布鲁克斯法则(Brook's Law)指出,投入更多的人来开发一个紧急的项目只会让进度更慢,更多并不意味着更好。投入新的人力时,要考虑训练和沟通成本。
141. 不同软件工程师之间的差别是很大的
- 最好的软件工程师和最差的软件工程师在产量(每人月代码行数)上能相差25倍,软件质量(每1000行代码的bug数)上能相差10倍
142. 可以优化任何方面
- 当你告诉员工 排期、软件大小、软件性能、可维护性、用户友好性都同等重要时,那么很可能哪方面都没有得到优化。当你告诉他们其中的一项或者两项比较重要时,可能只有重要的因素得到了优化。事实上在软件开发的过程中,这些因素的优先级可能会不断调整,需要进行不同的折中(trade-offs),你应该让员工理解这些优先级变化以及用户需求。
143. 自动收集工程师数据
- 收集工程师相关的数据有助于将来进行成本预测、评估项目状态和进展、评估改变(管理/技术/..)方案的影响。但数据收集应该尽可能自动化,最主要的是不唐突、不要让开发人员感到困扰。
144. 考虑每行代码的成本是没有意义的
- 相同的需求,可以使用不同的编程语言来完成。通常,使用高级语言会比低级语言节省开发时间,且缩短代码量;但由于用户文档、需求文档、设计文档等成本是固定的,最终会导致前者的单行代码成本增加。
145. 没有完美的衡量开发效率的方法
1. SLOC(source lines of code)代码行估算法:大家普遍认为代码产出越多越好,但有时候却并非如此。实现相同的功能,代码量肯定越少越好。
2. FP(function points)功能点估算法:大家可能认为功能点越多表示产出越多、效率越高,但所要解决的问题的复杂程度或难度不同也是会影响产出率的。
3. 没有哪一种方法是完美的,也不要单独依赖一种方法进行考量。
146. 调整成本估算方法
- 市面上有很多成本估算方法,每个方法都是基于大量已经完成的项目提炼出来的。你可以用这些方法估算大致的成本,但若想获得更准确的结果,则需要对模型或方法进行调整,使其适应你的工作环境(包括你的团队、你的产品等各种因素)。
147. 不要设定不切实际的deadline
- 不切实际的deadline会消解士气、降低员工对你的信任、导致员工离职等,会产生很多负面影响。这类deadline基本都无法达到,即使达到了,产品质量也无法保证,最终导致团队在整个软件领域的信誉度下降。
148. 避免不可能
- 从写需求分析文档到软件交付所需要的时间不会少于人月立方根的2.15倍,即 $T > 2.15 * \sqrt[3]{PM}$,因此不要制定不可能完成的计划
149. 使用之前必须了解
- 例如,在你在选择一套度量指标之前,你必须确保它能够度量你所想测的东西并能够达到你的目标
150. 收集生产数据:
- 没有历史生产数据就没有办法进行成本估算模型的调整和训练,也就不能进行准确的成本估计,因此数据收集要从平时做起。
151. 不要忘记团队生产力
- 相比团队生产力来说,个人生产力比较容易衡量。但是,提高每个成员的生产力并不一定能够提高整个团队的生产力。例如一个篮球队,每个球员的投篮命中率都很高,但并不意味着这个球队就能赢。可以从一段时间内团队解决突出问题的能力、所解决问题的难度等方法来考察团队效率。
152. 代码行数取决于编程语言
- 使用高级语言的效率一般会明显高于低级语言,例如500行Ada代码比500行汇编代码能实现更多的功能
153. 相信设定的时间表
1. 一旦制定好了计划和排期,就需要所有员工相信这个时间表的可行性,否则就很难成功。
2. 一个建议就是让工程师们来设定时间表,这种方法并非总是可行;另一个建议就是让工程师参与到时间表的制定中来,尤其需要在功能点、排期、放弃项目之间作出选择和折衷时。
154. 精心计算的成本估计也不是万无一失的
- 即使一个精心设计的估算模型得出的估算结果也未必准确。这里面有三个因素:(1)你 (2)假设条件 (3)概率。你的领导能力对结果影响很大,你可以在5秒钟摧毁你们团队1年建立起来的文化;你在进行估算时所作的前提假设可能会使结果不准确,如果你的需求变更了呢,如果你的核心成员生病了呢;估算结果只是整个概率分布中的一个峰值,其发生也是需要一定概率的。
155. 定期评估时间表
- 每个阶段的工作完成后都应该重新评估时间表,如果有delay的话,则需要及时调整时间表,不要妄图在后面的阶段追赶上来,否则只会让delay升级。试想如果每个阶段的期限都错过了,那么最后留给测试的时间就会越来越少,这样就可能出现两种不可避免的结果:(1)交付一个质量没有保障的产品,(2)客户在项目后期才了解到产品出现了很大的delay。因此,应该及时与业务方或上级领导沟通,告知他们排期的变动,并商讨对策,以降低损失。
156. 轻微的低估并非总是坏事
- 轻微的低估导致的轻微的delay能够督促队员更加努力赶上进度,从而提高生产力。注意,不能是明显的低估成本!
157. 合理分配资源
- 人为约束的时间表和不合理的预算都会导致项目的失败,不要试图压缩时间表和预算,否则最终可能需要付出比正常情况更多的成本。
158. 详细地计划项目
- 每个项目都需要一个计划,计划的详细程度取决于项目的复杂程度。项目越复杂,则需要计划越详细。
- 用PERT(Program Evaluation and Review Technique)图来表示各任务之间的依赖关系
- 用GANTT甘特图来显示每个任务的开始时间、结束时间及中间进度
- 设立一系列可实现的阶段性目标(milestones)
- 设定文档和代码编写规范
- 合理的人员及任务分配
159. 及时更新你的计划
160. 避免驻波
- 出现问题(delay、需求变更)及时调整计划和排期,不要等问题越积越多,越变越大
161. 了解十大风险
1. 人员短缺
2. 不切实际的时间表
3. 不理解需求
4. 构建了一个糟糕的用户界面
5. 试图增加用户不想要的feature
6. 没有把握需求变化
7. 缺少可重用的接口或组件
8. 缺少可外部执行的任务
9. 响应时间太差
10. 试图超过当前的计算机技术
162. 预先了解风险
- 项目初期,可以列出那些可能出现的比较大的风险,并量化其影响以及其出现的概率。可以构建一棵决策树来描述可能的风险以及规避/降低风险的方法。
163. 选择合适的开发模型
- 软件开发模型有很多:瀑布模型、抛弃型原型、增量开发、螺旋模型、业务原型等,但没有哪种模型能适用于所有项目。模型的选择可以基于公司文化、风险意愿、应用领域、需求波动以及对需求的理解程度等因素。
164. 方法并不能拯救你
- 方法并不是万能的。如果一个团队以前使用结构化的方法无法开发出高质量的软件,那么现在用面向对象的方法还是无法开发出高质量的软件,因为方法并不是问题。
165. 没有奇迹般地提高生产力的秘诀
- 不要轻信市面上那些宣称能够将生产力提高50%、75%甚至100%的工具、语言或方法。
166. 理解进度的含义
- BCWP(Budgeted cost of work performed),衡量目前已经完成的工作的预算
- ACWP(Actual cost of work performed),衡量目前的实际开销
- BCWE(Budgeted cost of work expected),衡量你预期的开销
- (BCWP-BCWE)/BCWE, 技术状态,大于0表示进度提前,小于0表示进度delay
- (BCWP-ACWP)/BCWP, 预算状态,大于0表示低于预算,小于0表示高于预算
167. 通过偏差进行管理
- 很多项目经理在汇报进度时总是花很多时间讲述他们做的有多好,这些话应该留在项目结束后的荣誉时刻再说。项目进行中,应该着重汇报实际进展与初始计划的偏差,这样注意力和资源才会被用于解决问题。
168. 不要过度紧张你的硬件
- 硬件的确会对软件产生很大的影响,当你有充足的硬件资源时,可以忽略这条原则;当你需要争取每一块内存、每一个cpu时,记得要相应调整软件开发的时间表。
169. 乐观看待硬件的发展
170. 悲观看待软件的发展
171. 认为灾难是不可能的想法往往导致灾难
- 过度自信往往是很多灾难的原因。
172. 要进行项目的事后分析
- 每个项目进行过程中都会遇到各种各样的问题,项目结束后应该及时检讨、总结经验教训,以期下次做的更好!
refer:《201 principles of software development》
Hexo 添加订阅、搜索和站点地图
简单记录下如何给Hexo网站添加RSS订阅功能、站内搜索功能以及站点地图。这些功能都需要相应的插件支持(Hexo插件参见 https://hexo.io/plugins/), 然后修改配置文件,最后需要重新部署。
添加RSS订阅功能
- 安装插件
npm install hexo-generator-feed --save - 在站点配置文件
_config.yml中追加如下代码:1
2
3
4
5
6
7
8feed:
type: atom
path: atom.xml
limit: 20
hub:
content:
content_limit: 140
content_limit_delim: ' '
- type - Feed type. (atom/rss2)
- path - Feed path. (Default: atom.xml/rss2.xml)
- limit - Maximum number of posts in the feed (Use 0 or false to show all posts)
- hub - URL of the PubSubHubbub hubs (Leave it empty if you don’t use it)
- content - (optional) set to ‘true’ to include the contents of the entire post in the feed.
- content_limit - (optional) Default length of post content used in summary. Only used, if content setting is false and no custom post description present.
- content_limit_delim - (optional) If content_limit is used to shorten post contents, only cut at the last occurrence of this delimiter before reaching the character limit. Not used by default.
添加站内搜索功能
- 安装插件
npm install hexo-generator-search --save - 在站点配置文件
_config.yml中追加如下代码:1
2
3
4# Search站内搜索
search:
path: search.xml
field: post
- path - file path. By default is search.xml . If the file extension is .json, the output format will be JSON. Otherwise XML format file will be exported.
- field - the search scope you want to search, you can chose:
- post (Default) - will only covers all the posts of your blog.
- page - will only covers all the pages of your blog.
- all - will covers all the posts and pages of your blog.
添加站点地图(Sitemap)
Sitemap 可方便网站管理员通知搜索引擎他们网站上有哪些可供抓取的网页。最简单的Sitemap形式,就是XML文件,在其中列出网站中的网址以及关于每个网址的其他元数据(上次更新的时间、更改的频率以及相对于网站上其他网址的重要程度为何等),以便搜索引擎可以更加智能地抓取网站。
简言之, Sitemap 对于搜索引擎优化(Search Engine Optimization,即SEO) 非常重要,在网站中加入 Sitemap 有利于搜索引擎的爬虫组件的抓取和收录网站内容。以下插件主要用于生成适用于谷歌和百度的sitemap文件。
1. 安装插件
1 | npm install hexo-generator-sitemap --save // 生成sitemap.xml |
2. 在站点配置文件_config.yml中追加如下代码:
1 | # SiteMap |
部署(hexo g)之后,如果public目录下生成了 sitemap.xml 和 baidusitemap.xml 就表示配置成功了。
3. 验证网站,并提交sitemap文件
在我们向搜索引擎提交 sitemap 之前,搜索引擎需要先验证我们对网站的所有权。两个搜索引擎的验证入口分别为:
具体验证及提交方法请参考:
Hello 我的半亩花田
大二暑假在csdn上注册了自己的第一个博客,从写题解开始,零零碎碎记了一些东西,但并没有坚持更博~
研究生之后因为比较忙,更是任自己的博客成了一片荒地~直到找工作时,才又开始写题解~
很早以前就想要建一个自己的独立博客,然而却因为忙一推再推…好吧,明明就是太懒…😅
今天我的Blog终于落成了!虽然还差一个域名…后面再补…😅

参考:
Hello World
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
Quick Start
Create a new post
1 | $ hexo new "My New Post" |
More info: Writing
Run server
1 | $ hexo server |
More info: Server
Generate static files
1 | $ hexo generate |
More info: Generating
Deploy to remote sites
1 | $ hexo deploy |
More info: Deployment