流控
流式计算系统中,任何中间节点的拥堵都可能会导致丢数据或系统雪崩,尤其是设计不够好的系统。设想这样一种数据流场景,A->B->C,B所依赖的外部存储挂了(redis/leveldb/rocksdb/hdfs)等,A->B层开始堆积数据,上下游以rpc+内存的方式传输,计算集群可能会大批量的OOM,最终导致整个系统雪崩。
流控(Flow Control),顾名思义,即流量控制,常见的思路有以下几种?
- 背压(Backpressure),就是消费者需要多少,生产者就生产多少。这有点类似于TCP里的流量控制,接收方根据自己的接收窗口的情况来控制接收速率,并通过反向的ACK包来控制发送方的发送速率。这种方案只对于cold Observable有效。cold Observable是那些允许降低速率的发送源,比如两台机器传一个文件,速率可大可小,即使降低到每秒几个字节,只要时间足够长,还是能够完成的。相反的例子就是音视频直播,速率低于某个值整个功能就没法用了(这种类似于hot Observable)。
- 节流(Throttling),说白了就是丢弃。消费不过来,就处理其中一部分,剩下的丢弃。至于处理哪些和丢弃哪些,就有不同的策略,也就是sample (or throttleLast)、throttleFirst、debounce (or throttleWithTimeout)这三种。还是举音视频直播的例子,在下游处理不过来的时候,就需要丢弃数据包。
- 打包(buffer和window),buffer和window基本一样,只是输出格式不太一样。它们是把上游多个小包裹打成大包裹,分发到下游。这样下游需要处理的包裹的个数就减少了。
- 是一种特殊情况,阻塞住整个调用链(Callstack blocking)。之所以说这是一种特殊情况,是因为这种方式只适用于整个调用链都在一个线程上同步执行,这要求中间的各个operator都不能启动新的线程。在平常使用中这种应该是比较少见的,因为我们经常使用subscribeOn或observeOn来切换执行线程,而且有些复杂的operator本身也会内部启动新的线程来处理。另外,如果真的出现了完全同步的调用链,前面的1、2、3仍然有可能适用的,只不过这种阻塞的方式更简单,不需要额外的支持。
下面简单介绍一下几种常见的流式系统中的背压机制。
Storm
对于开启了acker机制的Storm程序,可以通过设置conf.setMaxSpoutPending参数来实现反压效果,如果下游组件(bolt)处理速度跟不上导致spout发送的tuple没有及时确认的数超过了参数设定的值,spout会停止发送数据,这种方式的缺点是很难调优conf.setMaxSpoutPending参数的设置以达到最好的反压效果,设小了会导致吞吐上不去,设大了会导致worker OOM;有震荡,数据流会处于一个颠簸状态,效果不如逐级反压;另外对于关闭acker机制的程序无效.
Heron(新版storm)自动反压机制(Automatic Back Pressure)通过监控Bolt中的接收队列的负载情况,如果超过高水位就会将反压信息写入zk,zk上的watch就会通知该拓扑的所有worker进入反压,最后Spout停止发送数据,直到接收队列的负载降到低水位以下。这种方式存在的问题就是, 当下游出现阻塞时, 上游停止发送, 下游消除阻塞后,上游又开闸放水,过了一会儿,下游又阻塞,上游又限流, 如此反复, 整个数据流一直处在一个颠簸状态。具体实现:JIRA STORM-886
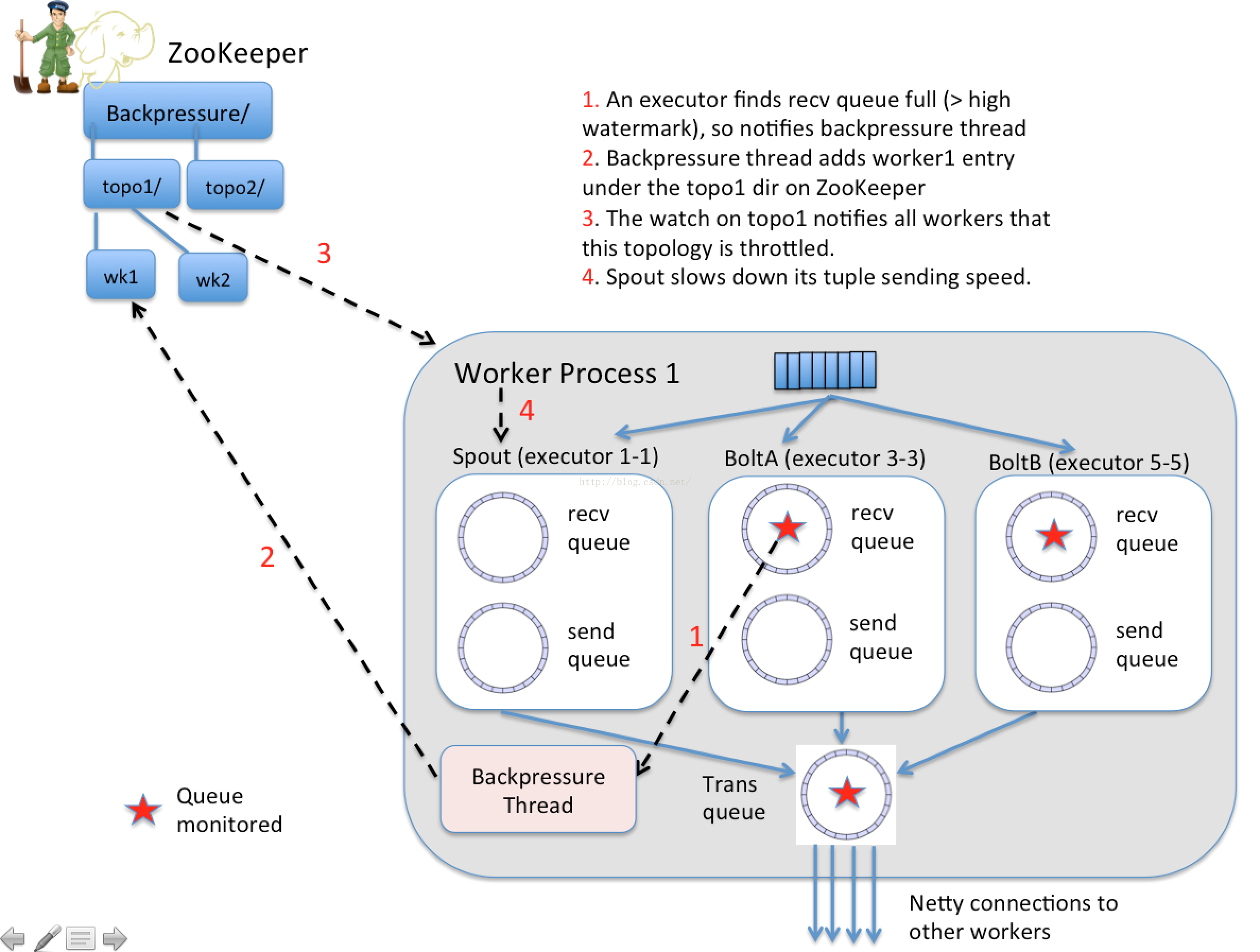
Jstorm的改进方案是逐级降速与放水来进行反压;另外,Jstorm没有引入zk,而是通过TopologyMaster来协调拓扑进行反压。
Spark Streaming
Spark Streaming程序中当计算过程中出现batch processing time > batch interval的情况时,(其中batch processing time为实际计算一个批次花费时间,batch interval为Streaming应用设置的批处理间隔),意味着处理数据的速度小于接收数据的速度,如果这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟),可以通过设置参数spark.streaming.receiver.maxRate来限制Receiver的数据接收速率,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。为了更好的协调数据接收速率与资源处理能力,Spark Streaming 从v1.5开始引入反压机制(back-pressure),通过动态控制数据接收速率来适配集群数据处理能力.
Spark Streaming Backpressure: 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。通过属性”spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
Spark Streaming的执行流程如下图所示: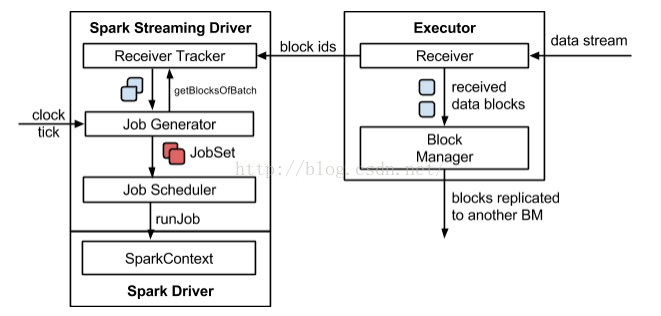
其背压流程如下:在原架构的基础上加上一个新的组件RateController,这个组件负责监听“OnBatchCompleted”事件,然后从中抽取processingDelay 及schedulingDelay信息. Estimator依据这些信息估算出最大处理速度(rate),最后由基于Receiver的Input Stream将rate通过ReceiverTracker与ReceiverSupervisorImpl转发给BlockGenerator(继承自RateLimiter).
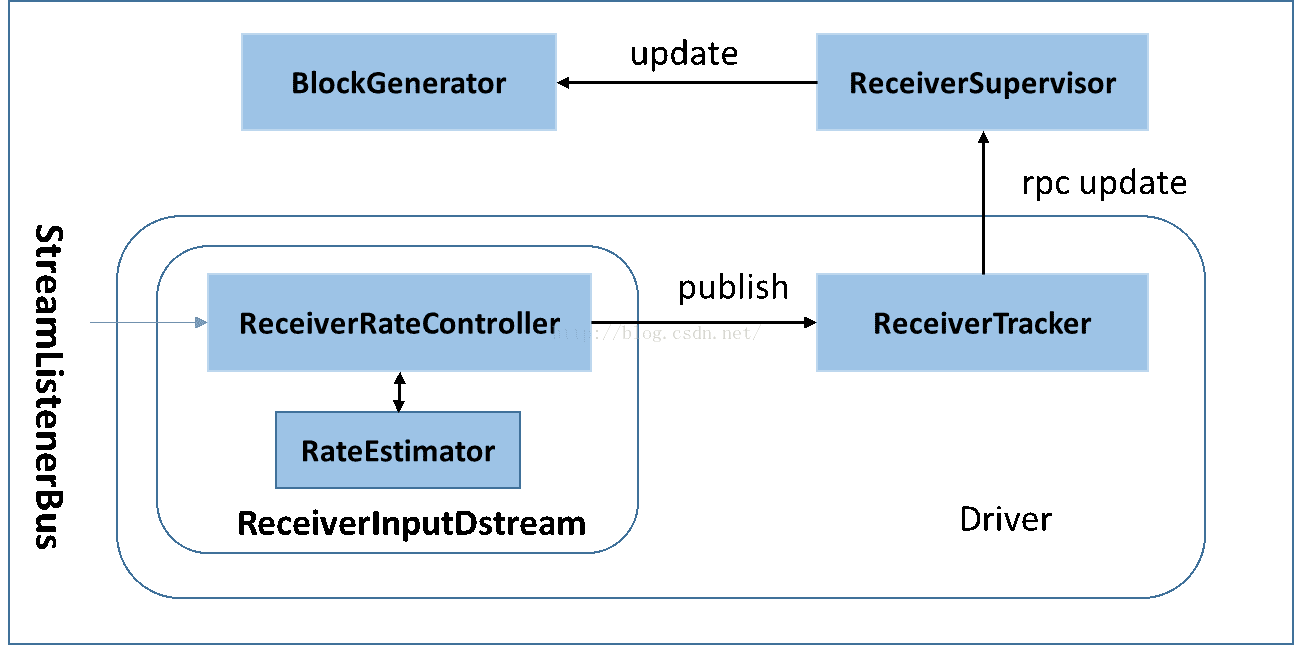
Flink
内存模型
Flink运行时的构造部件是operators以及streams。每一个operator消费一个中间/过渡状态的流,对它们进行转换,然后生产一个新的流。两个相邻的operator之间使用有效的分布式阻塞队列来作为有界的缓冲区。如同Java里通用的阻塞队列跟处理线程进行连接一样,一旦队列达到容量上限,一个相对较慢的接受者将拖慢发送者。在Flink中这些分布式的队列被认为是逻辑流,而它们的有界容量可以通过每一个生产、消费流管理的缓冲池获得。缓冲池是缓冲区的集合,它们都可以在被消费完之后循环利用。这个观点很好理解:你从池里获取一个缓冲区,填进数据,然后在数据被消费后,将该缓冲区返还回缓冲池,之后你还可以再次使用它。
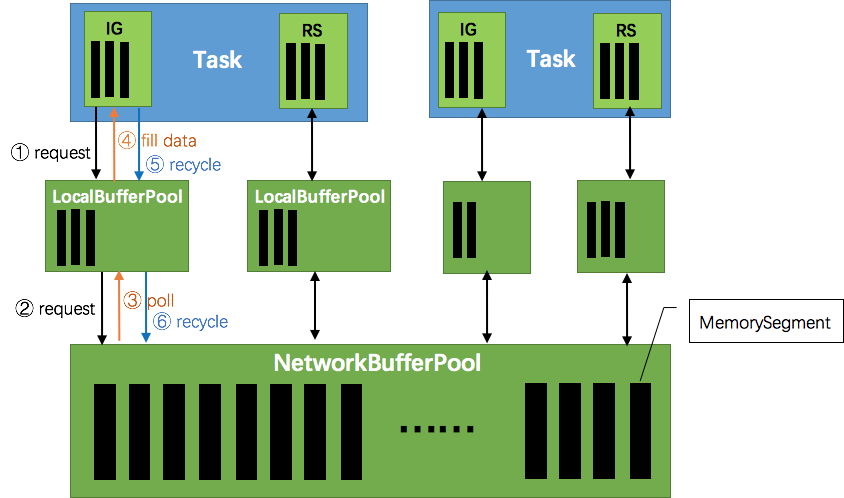
这些缓冲池的大小在运行时能动态变化。在不同的发送者/接收者存在不同的处理速度的情况下,网络栈里的内存缓冲区的数量(等于队列的容量)决定了系统能够提供的缓冲区的数量。Flink保证总是有足够的缓冲区提供给应用程序,但处理的速度是由用户的程序以及可用内存的数量决定的。内存越多,意味着系统可以轻松应对一定的瞬时背压(short periods,short GC)。越少的内存意味着需要对背压进行更多的“即时”响应(意思是,如果内存少缓冲区就容易被填满,那么需要立即作出响应,消费走数据才能应对这个问题)。
背压示例
下面这张图简单展示了两个 Task 之间的数据传输以及 Flink 如何感知到反压的:
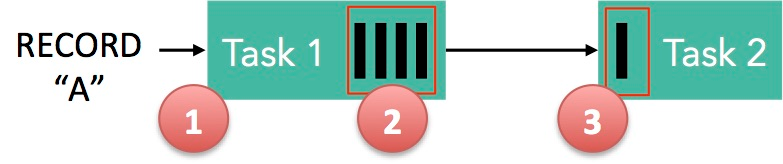
- 记录“A”进入了 Flink 并且被 Task 1 处理。(这里省略了 Netty 接收、反序列化等过程)
- 记录被序列化到 buffer 中。
- 该 buffer 被发送到 Task 2,然后 Task 2 从这个 buffer 中读出记录
结合上面两张图看:Task 1 在输出端有一个相关联的 LocalBufferPool(称缓冲池1),Task 2 在输入端也有一个相关联的 LocalBufferPool(称缓冲池2)。如果缓冲池1中有空闲可用的 buffer 来序列化记录 “A”,我们就序列化并发送该 buffer。
这里我们需要注意两个场景:
本地传输:如果 Task 1 和 Task 2 运行在同一个 worker 节点(TaskManager),该 buffer 可以直接交给下一个 Task。一旦 Task 2 消费了该 buffer,则该 buffer 会被缓冲池1回收。如果 Task 2 的速度比 1 慢,那么 buffer 回收的速度就会赶不上 Task 1 取 buffer 的速度,导致缓冲池1无可用的 buffer,Task 1 等待在可用的 buffer 上。最终形成 Task 1 的降速。
远程传输:如果 Task 1 和 Task 2 运行在不同的 worker 节点上,那么 buffer 会在发送到网络(TCP Channel)后被回收。在接收端,会从 LocalBufferPool 中申请 buffer,然后拷贝网络中的数据到 buffer 中。如果没有可用的 buffer,会停止从 TCP 连接中读取数据。在输出端,通过 Netty 的水位值机制来保证不往网络中写入太多数据(后面会说)。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数据(由于接收端缓冲池没有可用 buffer),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。另外,这会使得发送端的缓冲池得不到回收,writer 阻塞在向 LocalBufferPool 请求 buffer,阻塞了 writer 往 ResultSubPartition 写数据。
这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快于消费的速度。我们上面描述的这个方案可以从两个Task之间的数据传输自然地扩展到更复杂的 pipeline 中,保证背压机制可以扩散到整个pipeline。
总结
相较于Storm和Spark-Streaming通过监控上下游算子的处理速度以及数据堆积情况来进行背压,Flink的背压机制则更加自然简洁,无需增加额外的监控组件,也无需Zookeeper/TopologyMaster的参与,对于流量的控制和恢复响应更迅速。类似木桶原理,Flink所获得的最大吞吐量由其pipeline中最慢的operator决定。
Refer
https://www.zhihu.com/question/49618581
https://blog.csdn.net/yanghua_kobe/article/details/51214097
http://blog.csdn.net/cm_chenmin/article/details/52936575
http://wuchong.me/blog/2016/04/26/flink-internals-how-to-handle-backpressure/