架构
Flink集群启动后的架构如下图所示: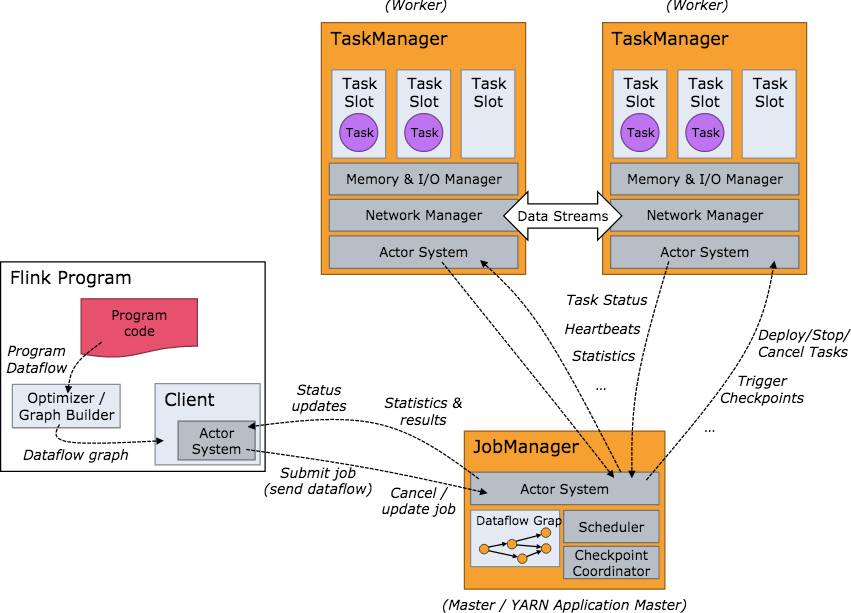
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,即一个线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
可以看到 Flink 的任务调度是多线程模型,并且不同Job/Task混合在一个 TaskManager 进程中。虽然这种方式可以有效提高 CPU 利用率,但是缺乏资源隔离机制,同时也不方便调试。类似 Storm 的进程模型,一个JVM 中只跑该 Job 的 Tasks 实际应用中更为合理。
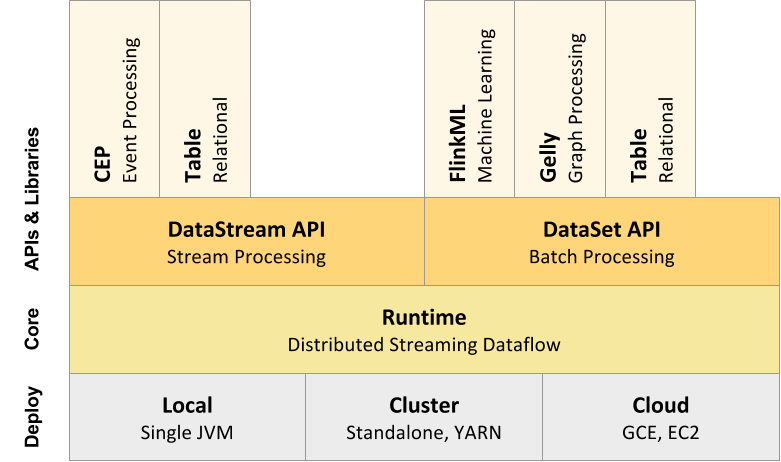
内存管理
如今,大数据领域的开源框架(Hadoop,Spark,Storm)都使用的 JVM,当然也包括 Flink。基于 JVM 的数据分析引擎都需要面对将大量数据存到内存中,这就不得不面对 JVM 存在的几个问题:
Java 对象存储密度低。一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个bit(1/8字节)就够了。
Full GC 会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC 会达到秒级甚至分钟级。
OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
所以目前,越来越多的大数据项目开始自己管理JVM内存了,像 Spark、Flink、HBase,为的就是获得像 C 一样的性能以及避免 OOM 的发生。本文将会讨论 Flink 是如何解决上面的问题的,主要内容包括内存管理、定制的序列化工具、缓存友好的数据结构和算法、堆外内存、JIT编译优化等。
容错机制
refer: https://www.iteblog.com/archives/1987.html
Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。
容错机制通过持续创建分布式数据流的快照来实现。对于状态占用空间小的流应用,这些快照非常轻量,可以高频率创建而对性能影响很小。流计算应用的状态保存在一个可配置的环境,如:master 节点或者 HDFS上。
在遇到程序故障时(如机器、网络、软件等故障),Flink 停止分布式数据流。系统重启所有 operator ,重置其到最近成功的 checkpoint。输入重置到相应的状态快照位置。保证被重启的并行数据流中处理的任何一个 record 都不是 checkpoint 状态之前的一部分。
注意:为了容错机制生效,数据源(例如 消息队列 或者 broker)需要能重放数据流。Apache Kafka 有这个特性,Flink 中 Kafka 的 connector 利用了这个功能。由于 Flink 的 checkpoint 是通过分布式快照实现的,接下来我们将 snapshot 和 checkpoint 这两个词交替使用。
Window机制
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
窗口可以是时间驱动的(例如30s为一个时间窗口),也可以是数据驱动的(例如100个元素为一个窗口)。一种经典的窗口分类可以分成:翻滚窗口(Tumbling Window/Fixed Window,无重叠),滑动窗口(Sliding Window,有重叠),和会话窗口(Session Window,活动间隙)。Flink提供了Tumbling Time Window, Sliding Time Window, Tumbling Count Window, Session Window。
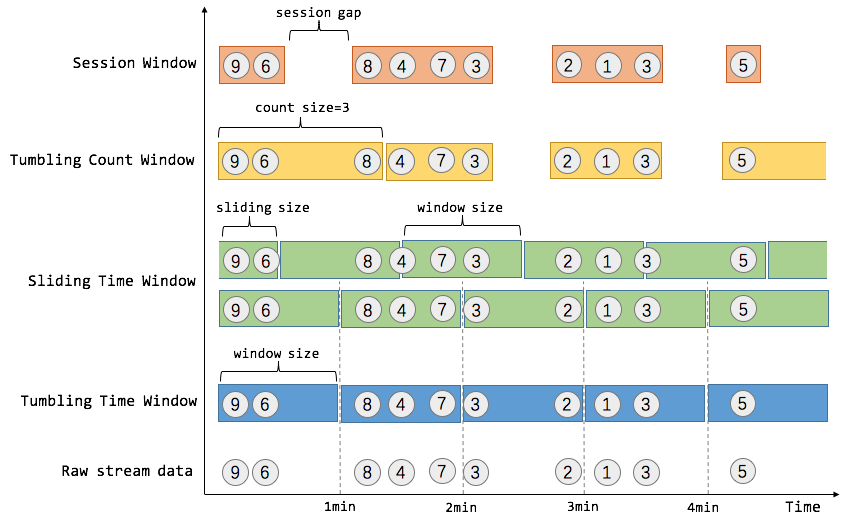
1. Time Window
Flink中主要涉及三种时间概念,event time(事件发生的时间), ingestion time(事件进入流处理系统的时间),processing time(消息被处理的时间)。窗口机制与时间类型完全解耦,即当需要改变时间类型时,不需要更改窗口逻辑。
Tumbling Time Window 例如,我们需要统计每一分钟中用户进行搜索的次数,需要将用户的行为事件按每一分钟进行切分,这样切分出来的窗口就是翻滚窗口/固定窗口。翻滚窗口能将数据流切分成不重叠的窗口,每个事件只能属于一个窗口。
Sliding Time Window 对于某些应用,他们需要平滑地进行窗口聚合。例如,我们可以每30秒计算一次最近一分钟用户可以购买的商品总数。这种窗口我们称为滑动窗口。在滑动窗口中,一个元素可以对应多个窗口。
2. Count Window
Tumbling Count Window 如果想对每100个用户的搜索行为统计总数,那么每当窗口中填满100个元素,就对窗口进行计算,这种窗口我们称之为翻滚计数窗口。
Sliding Count Window 如果想进行更平滑的聚合,每10个元素计算一次最近100个元素的搜索总数,这种窗口就是滑动计数窗口。
3. Session Window
在用户交互事件流中,我们首先想到的是将事件聚合到会话窗口中(一段用户持续活跃的周期),由非活跃的间隙分隔开。如下图所示,就是需要计算每个用户在活跃期间总共搜索的记录数,如果用户30秒没有活动则视为会话断开(假设raw data stream是单个用户的搜索行为流)。

对于session window来说,我们需要窗口变得更灵活。基本的思想是这样的:SessionWindows assigner 会为每个进入的元素分配一个窗口,该窗口以元素的时间戳作为起始点,时间戳加会话超时时间为结束点,也就是该窗口为[timestamp, timestamp+sessionGap)。比如我们现在到了两个元素,它们被分配到两个独立的窗口中,两个窗口目前不相交,如图:

当第三个元素进入时,分配到的窗口与现有的两个窗口发生了叠加,情况变成了这样:

需要注意的是,对于每一个新进入的元素,都会分配一个属于该元素的窗口,都会检查并合并现有的窗口。在触发窗口计算之前,每一次都会检查该窗口是否可以和其他窗口合并,直到trigger触发后,会将该窗口从窗口列表中移除。对于 event time 来说,窗口的触发是要等到大于窗口结束时间的 watermark 到达,当watermark没有到,窗口会一直缓存着。所以基于这种机制,可以做到对乱序消息的支持。
一般而言,window是在无限的流上定义了一个有限的元素集合。这个集合可以是基于时间的,元素个数的,时间和个数结合的,会话间隙的,或者是自定义的。Flink 的 DataStream API提供了简洁的算子来满足常用的窗口操作,同时提供了通用的窗口机制来允许用户自己定义窗口分配逻辑。
4. Window API
- Window Assigner: 用来决定某个元素被分配到哪个/哪些窗口中
- Trigger:触发器。决定一个窗口何时能够被计算或清除,每个窗口都会有一个自己的Trigger
- Evictor:在Trigger被触发后,在窗口被处理之前,Evictor(如果有Evictor的话)会用来剔除窗口中不需要的元素,相当于一个filter。
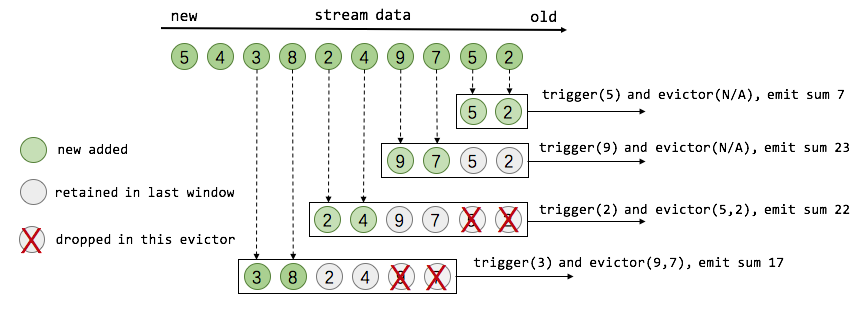
5. watermark
当operator通过基于Event Time的时间窗口来处理数据时,它必须在确定所有属于该时间窗口的消息全部流入该operator时才能开始数据处理。但是由于消息可能是乱序的,所以无法直接确认何时所有属于该时间窗口的消息全部流入此operator。Watermark就是用来支持基于Event Time的窗口计算的。
Watermark包含一个时间戳,Flink使用Watermark标记所有小于该时间戳的消息都已流入,Flink的数据源在确认所有小于某个时间戳的消息都已输出到Flink流处理系统之后,会生成一个包含该时间戳的Watermark,插入到消息流中输出到Flink流处理系统中,Flink operator按照时间窗口缓存所有流入的消息,当operator处理到Watermark时,它对所有小于该Watermark时间戳的时间窗口数据进行处理并发送到下一个operator节点,然后也将Watermark发送到下一个operator.
为了保证能够处理所有属于某个时间窗口的消息,操作符必须等到大于这个时间窗口的WaterMark之后才能开始对该时间窗口的消息进行处理,相对于基于Operator Time的时间窗口,Flink需要占用更多内存,且会直接影响消息处理的延迟时间。对此,一个可能的优化措施是,对于聚合类的操作符,可以提前对部分消息进行聚合操作,当有属于该时间窗口的新消息流入时,基于之前的部分聚合结果继续计算,这样的话,只需缓存中间计算结果即可,无需缓存该时间窗口的所有消息。
6. 窗口计算流程
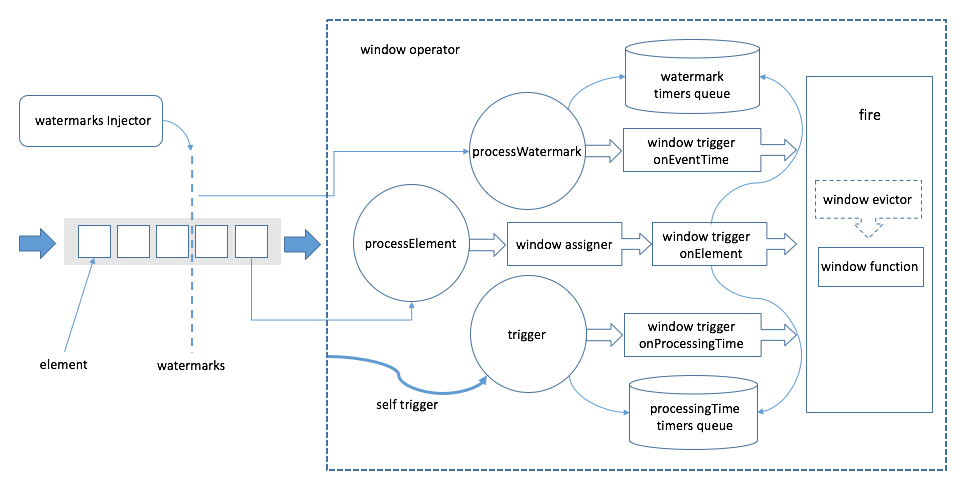
上图中,左侧从左往右为事件流的方向。方框代表事件,事件流中夹杂着的竖直虚线代表watermark,Flink通过watermark分配器(TimestampsAndPeriodicWatermarksOperator和TimestampsAndPunctuatedWatermarksOperator这两个算子)向事件流中注入watermark。元素在streaming dataflow引擎中流动到WindowOperator时,会被分为两拨,分别是普通数据和watermark。
如果是普通数据,则会调用processElement方法(上图虚线框中的三个圆圈中的一个)进行处理,在processElement方法中,首先会利用窗口分配器为当前接收到的元素分配窗口,接着会调用触发器的onElement方法进行逐元素触发。对于时间相关的触发器,通常会注册事件时间或者处理时间定时器,这些定时器会被存储在WindowOperator的处理时间定时器队列和watermark定时器队列中(见图中虚线框中上下两个圆柱体),如果触发的结果是fire,则对窗口进行计算。
如果是watermark(事件时间场景),则方法processWatermark将会被调用,它将会处理watermark定时器队列中的定时器。如果时间戳满足条件,则利用触发器的onEventTime方法进行处理。
而对于处理时间的场景,WindowOperator将自身实现为一个基于处理时间的触发器,以触发trigger方法来消费处理时间定时器队列中的定时器满足条件则会调用窗口触发器的onProcessingTime,根据触发结果判断是否对窗口进行计算。
Refer
关于watermark的提问:https://blog.csdn.net/lmalds/article/details/52704170
关于数据交换的提问:https://blog.csdn.net/yanghua_kobe/article/details/51235544
关于定时器的提问:https://blog.csdn.net/yanghua_kobe/article/details/52966156
关于滑动窗口的提问:https://blog.csdn.net/wwwxxdddx/article/details/51706900
http://wuchong.me/blog/2016/05/03/flink-internals-overview/
http://doc.flink-china.org/latest/concepts/programming-model.html