2019.11.28~2019.11.29 参加了Flink Forward Asia 2019大会,大家对实时计算热情很高,参会人数及企业都很多。会议一共持续一天半,第一天上午是主会场,第一天下午和第二天上午是分会场,分会场的话有核心技术、企业实践、实时数仓、开源大数据生态、人工智能五个分会场并行,我主要穿梭在核心技术和实时数仓两个分会场。下面先简单介绍下Flink的前世今生,以及会场上我听的几个topic.
Flink 发展历程
- Apache Flink项目在捐献给Apache之前,是由柏林工业大学博士生发起的项目,当时的Flink系统还是一个基于流式Runtime的批处理引擎,主要解决的也是批处理的问题。
- 2014年,Flink被捐献给Apache,并迅速成为Apache 的顶级项目之一。
- 2014年8月份,Apache发布了第一个Flink版本,Flink 0.6.0,在有了较好的流式引擎支持后,流计算的价值也随之被挖掘和重视;同年12月,Flink发布了0.7版本,正式推出了DataStream API,这也是目前Flink应用的最广泛的API。
- Flink 0.9中引入了Global Checkpoint机制以保证exactly-once语义,主要基于经典的Chandy-Lamport算法进行的改进。Flink 会在数据源中定期插入Barrier,框架在看到 Barrier 后会对本地的 State 做一个快照,然后再将 Barrier 往下游发送。
- Flink 1.0 版本加入了基于事件时间的计算支持,引入了 Watermark 机制,可以高效的容忍乱序数据和迟到数据。Flink 1.0同时还内置支持了各种各样的 window,开箱即用的滚动、滑动、会话窗口等,还可以灵活地自定义窗口。
- 2015年之后,阿里巴巴开始注意到 Flink 计算引擎,并且非常认可 Flink 系统设计理念的先进性,看好其发展前景,因此阿里巴巴内部开始大量使用 Flink,同时也对 Flink 做了大刀阔斧的改进,形成了内部版,即Blink
- 2018 年双 11,阿里巴巴Flink服务规模已经超过万台集群。单作业已经达到了数十 TB 的状态数据,所有的作业加起来更是达到了 PB 级。每天需要处理超过十万亿的事件数据。在双 11 的零点峰值时,数据处理量已经达到了 17 亿条每秒。
- 目前 Flink 最新的版本是1.9,Flink 在这个版本上做了较大的架构调整。首先,Flink 之前版本的 Table API 和 SQL API 是构建于两个底层的API 之上,即 DataStream API 和 DataSet API。Flink 1.9 经历了较大的架构调整之后,Table API 和 DataStream API 已成为同级的 API。不同之处在于 DataStream API 提供的是更贴近物理执行计划的 API,引擎完全基于用户的描述能执行作业,不会过多的进行优化和干预。Table API 和 SQL 是关系表达式 API,用户使用这个 API 描述想要做一件什么事情,由框架在理解用户意图之后,配合优化器翻译成高效的具体
执行图。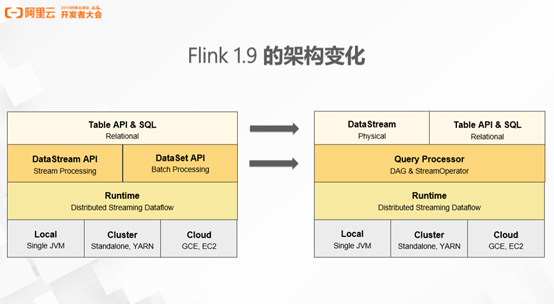
详见:https://yq.aliyun.com/articles/712192?type=2
引擎一体化和生态多元化是 Flink 一以贯之的发展策略。引擎一体化指的是离线(batch),实时(streaming)和在线(application)应用在执行层面的一体化。生态多元化指的是对 AI 生态环境的搭建和对更多生态的支持,包括 Hive,Python,Kubernetes 等。
主会场
1. Stateful Functions:Building general-purpose Applications and Services on Apache Flink
Stephan 继续推广他对 Flink 作为应用服务场景(Applications and Services)通用引擎的展望和规划。简而言之,他认为 Flink 除了能够做到批流一体,Flink 框架对于事件驱动的在线应用也可以有效甚至更好的支持,如下图所示:
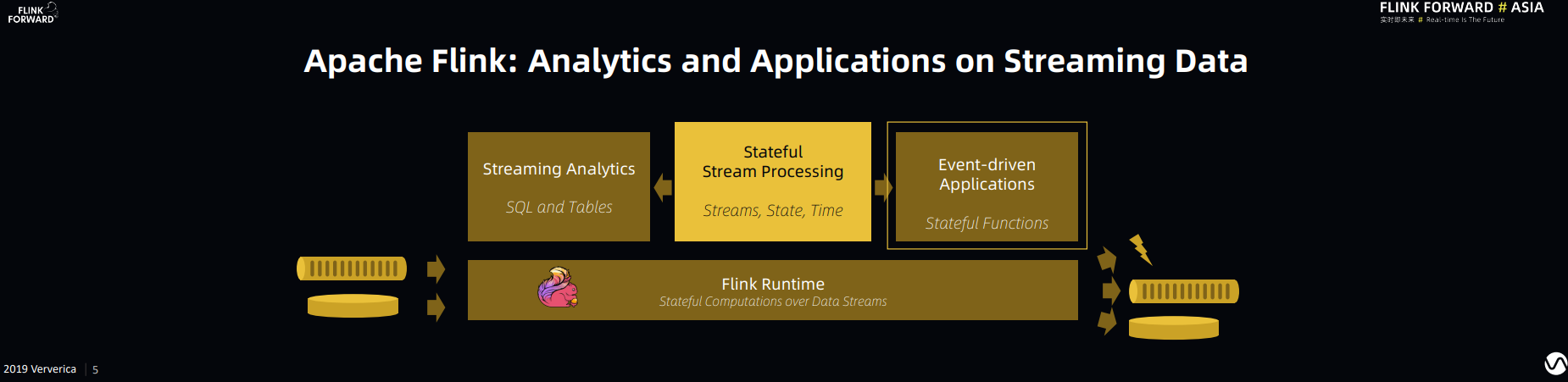
云上对此类问题的一种主流的解决方案便是FaaS。FaaS是Function as a Service的缩写,可以简单理解为功能服务化。FaaS提供了一种比微服务更加服务碎片化的软件架构范式。FaaS可以让研发只需要关注业务代码逻辑,不再关注技术架构。以微服务为核心的前后端分离,业务积木装配式技术架构。但目前仍有以下几个方面的痛点:
(1)Bottlenecked by state access & I/O
(2)State Consistency Problem
(3)Scalability of Database (storing the states)
(4)Connections and Request rates
特别是在应用逻辑非常复杂的情况下,应用逻辑之间的组合调用会更加复杂,并且加剧上面四个痛点的复杂度。同时你会发现上面的这些问题都和State 的存储(storage),读写(access)以及一致性(consistency)相关,而 Flink 的 Stream Processing 框架可以很好的解决这些和状态相关的问题。所以 Stateful Function 在 Flink 现有的框架上拓展了对 Function Composition 和 Virtual Instance(轻量级的 Function 资源管理)的支持,以达到对应用服务场景(Application)的通用支持。

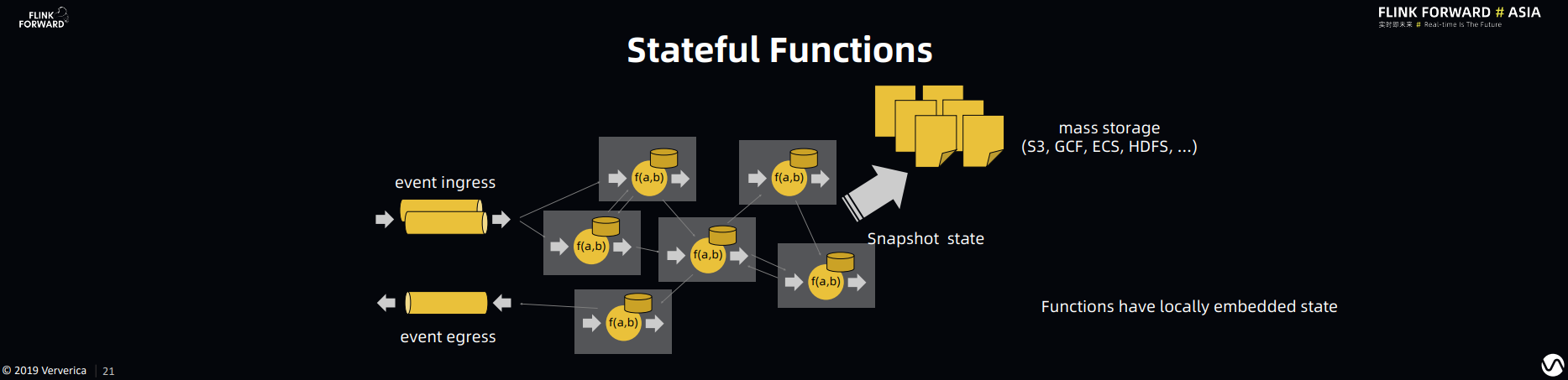
可以从两个维度理解 Stateful Function:
1. Stateful Function 到底要解决什么问题
2. 为什么 Stateful Function 比现有的解决方案更好
关于第一个问题举例说明,假设我们使用Lyft打车服务。在乘客发起打车请求以后,Lyft 首先会根据乘客的定位,空闲司机的状态,目的地,交通状况和个人喜好给乘客推荐不同类型车辆的定价。在乘客选择定价以后,Lyft 会根据乘客的喜好(比如有些司机被乘客拉了黑名单),司机的喜好(乘客也有可能被司机拉了黑名单),司机和乘客的相对位置以及交通状况进行匹配,匹配完成后订单开始。在这个例子中,我们会发现:
- 有很多 Function Composition:乘客的喜好的计算,司机的喜好计算,司机和乘客相对位置计算,交通状况计算,以及最终匹配计算,这些计算都是带有状态的计算
- 状态的一致性的重要:在匹配的过程中如果发生错误,在保持状态一致性的情况下回滚非常重要。我们不希望一个乘客匹配给两个司机,也不希望一个司机匹配给两个乘客,更不希望乘客或者司机因为一致性问题无法得到匹配。
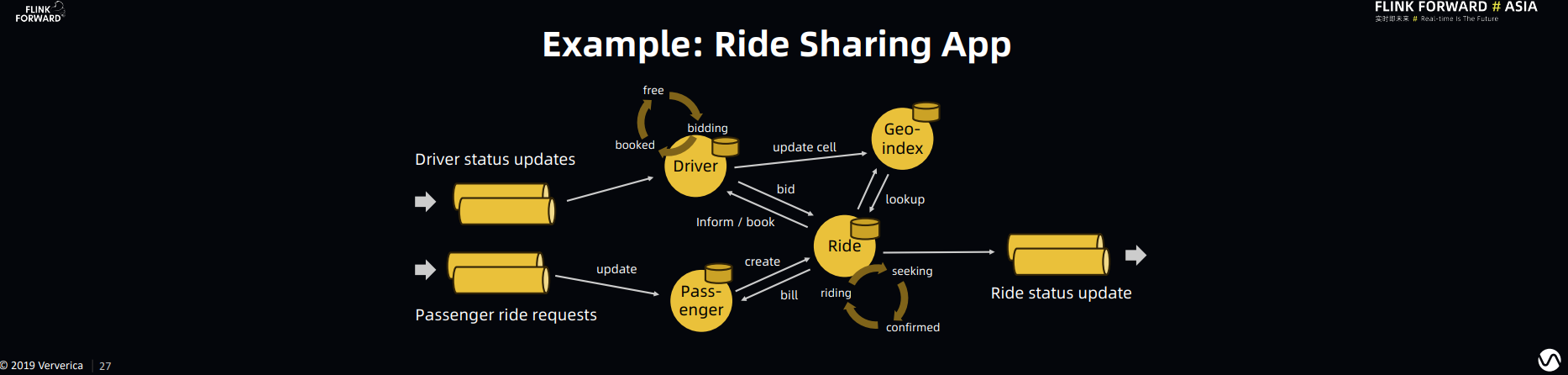
Stateful Function 在 Flink 开源 Runtime 的基础上很好的解决了 Function Composition 和 State Consistency 的问题。
关于第二个问题:为什么 Stateful Function 比现有的解决方案更好。我的理解是 Stateful Function 提供了更清晰的 abstraction。Stateful Function 把消息传输、状态管理从 Function 中隔离出来,使得用户只需要关注 Function 计算逻辑本身,而不需要关注 Function 的调度,组合等问题,这也使得Stateful Function 框架能有更多的自由度为 Function 调度组合等问题做优化。
关于打车,我记得Uber要用Flink做实时异常检测,检测司机或乘客是否发生了车祸
FaaS的具体技术实现以及如何实现Function之间任意通信(不限于DAG)我还不太清楚,后面有时间再看一下
2. Apache Flink Heading Towards A Unified Engine
阿里实时计算负责人莫问认为未来 Flink 的发展趋势是一体化:包括离线(batch),实时(streaming)和在线(application)一体化。在此基础上,也需要把拥抱 AI 和云原生纳入到一体化中。
对于批流融合,通过 1.9 和 1.10 两个版本的发布,Flink 在 SQL 和 Table API 的层面以及 Flink runtime 层面对批流模式已经做到统一。对于 Flink SQL,在 1.10 这个版本里面,已经可以实现完整的 DDL 功能,兼容 Hive 生态系统并且支持 Python UDF。总的来说就是:
- Flink SQL 在批模式下经过多方验证已经达到生产可用的状态。
- Flink SQL 可以在Hive 生态上直接运行,没有迁移成本。
- Flink SQL 可以做到批流在SQL 优化、算子层以及分布式运行层的一体化。
跑 TPC-DS benchmark,Flink 1.10 比 Hive-3.0 快 7 倍?
在 AI 部分,2019 Flink 重点主要在优化和铺垫 AI 的基础设施部分:
- Flink 1.9 发布一套标准化的 Machine Learning Pipeline API(这个 pipeline 的概念最早在 Scikit-learn 中提出,在其他生态中也有广泛的采纳)。AI 的开发人员可以使用这套 API(Transformer,Estimator,Model)来实现机器学习算法。
- 更好的支持 Python 生态。Flink 1.10 在 Table API 中可以支持 Python UDF,复用了 Beam 的 Python 框架来进行 Java 和 Python 进程之间的通讯。
- Alink 开源发布。Alink 是基于 Flink 的机器学习算法库,最大的亮点是对流式和在线学习的支持。
在 AI 部分还有一个很值得期待的项目是Flink AI 明年的一个重点投入方向:AI Flow。AI Flow 为 AI 链路定制了一套完整的解决方案:包括从 data acquisition,preprocessing,到 model training & validation & serving 以及 inference 的一整套链路。这个方案是针对解决现在 AI 链路里面数据预处理复杂,离线训练和在线预测脱钩等问题定制的
另一个重要方向就是对云原生生态的支持,即与Kubernetes 生态的深度融合。Kubernetes 环境可以在 multi-user 的场景下提供更好的隔离,对 Flink 在生产的稳定性方面会有所提升。Kubernetes 广泛应用在各种在线业务上,Flink 与 Kubernetes 的深度融合可以在更大范围内统一管理运维资源。
3. Reliable Streaming Infrastructure for the Enterprise
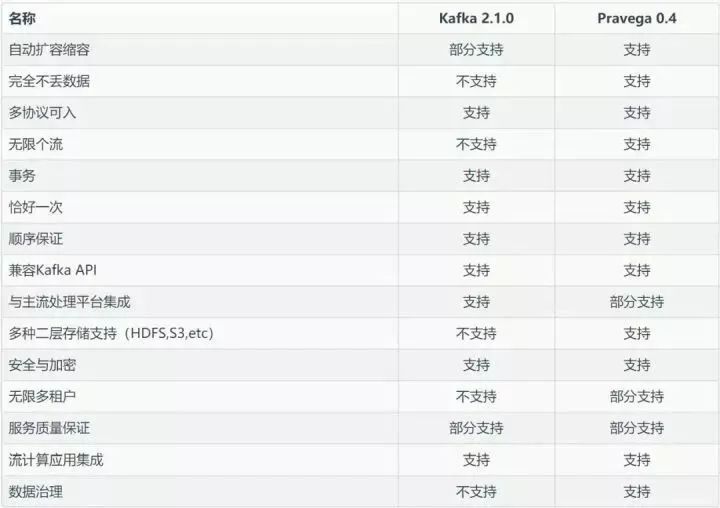
第三个议题是由戴尔科技集团带来的流式存储议: Pravega,他们的主要观点是随着流式计算在大企业用户中越来越广泛的应用,流式计算对存储也产生了新的需求:“计算是原生的流计算,而存储却不是原生的流存储” 。Pravega 团队重新思考了这一基本的数据处理和存储规则,为这一场景重新设计了一种新的存储类型,即原生的流存储,命名为”Pravega”,取梵语中“Good Speed”之意。
该项目为开源项目,想了解具体实现可查看 https://github.com/pravega/pravega/
关于Pravega我查了一些资料,印象比较深的一点是:Pravega能够应对瞬时的数据洪峰,做到“削峰填谷”,让系统自动地伴随数据到达速率的变化而伸缩,既能够在数据峰值时进行扩容提升瞬时处理能力,又能在数据谷值时进行缩容节省运行成本,而读写客户端无需额外进行调整。这一特性对于企业特别是云端业务尤为重要。Kafka和bigpipe都是需要手动扩缩容的。
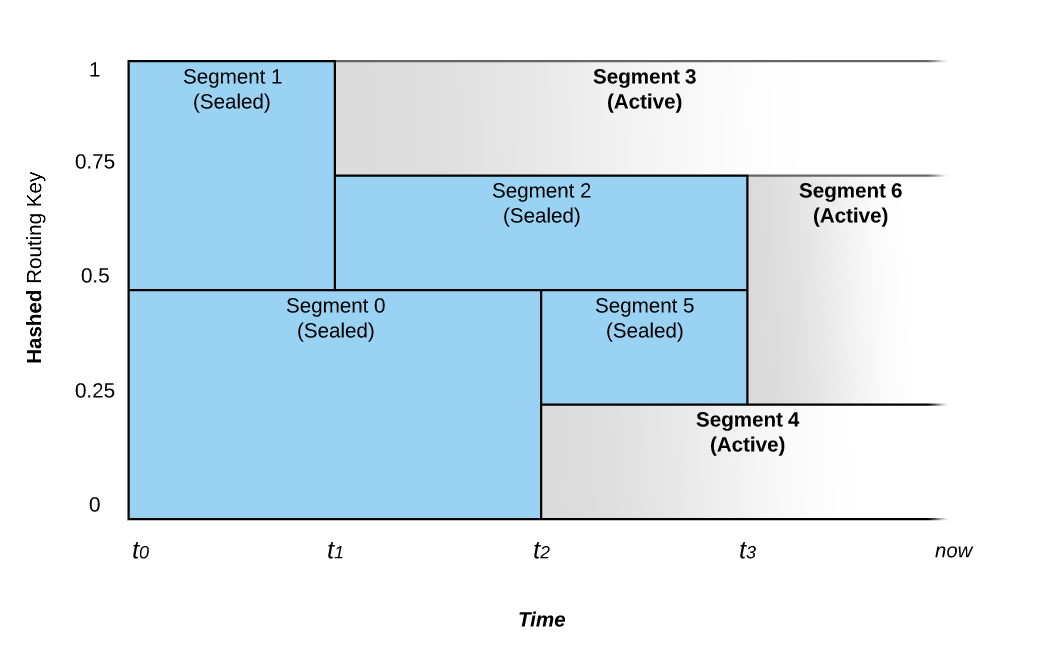
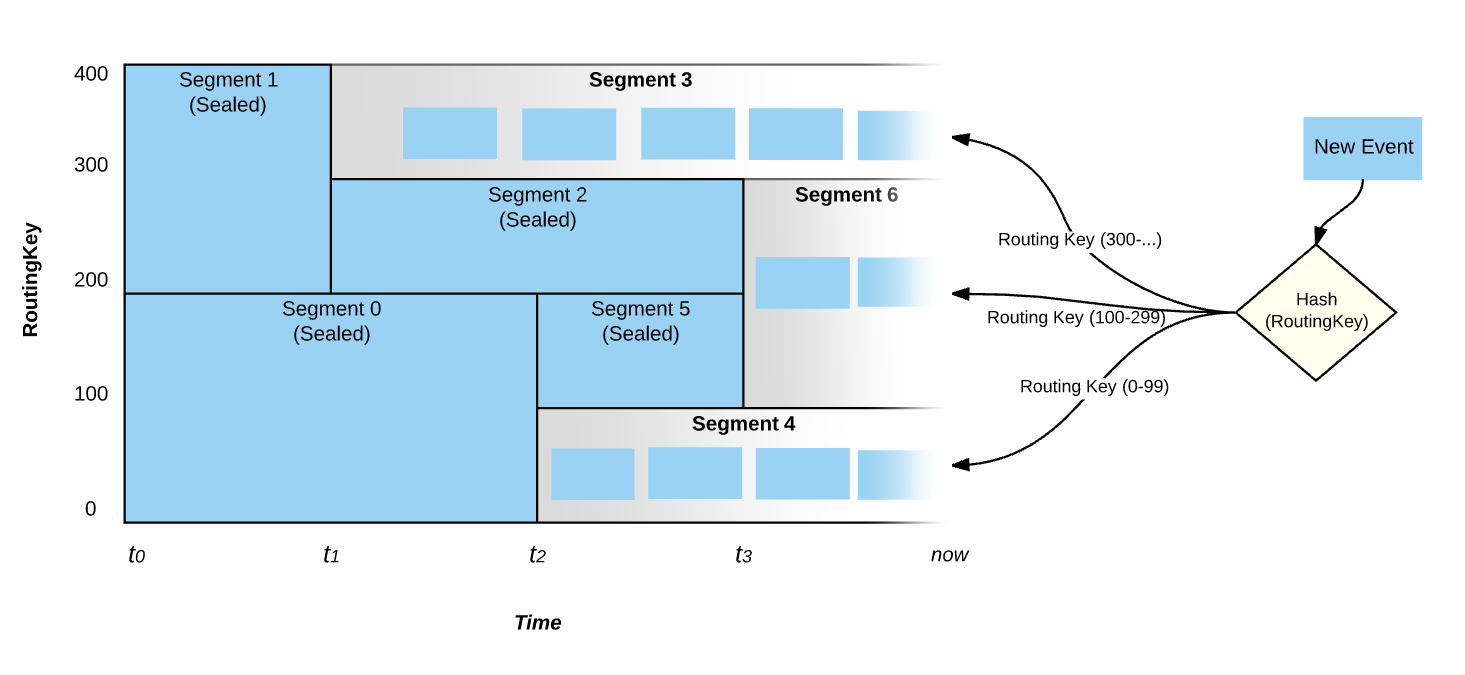
Pravega 是从存储的视角来看待流数据,而 Kafka 本身的定位是消息系统而不是存储系统,它是从消息的视角来看待流数据。消息系统与存储系统的定位是不同的,简单来说,消息系统是消息的传输系统,关注的是数据传输与生产消费的过程。Pravega 的定位就是企业级的分布式流存储产品,除了满足流的属性之外,还需要满足数据存储的持久化、安全、可靠性、一致性、隔离等属性,关注数据的生产、传输、存放、访问等整个数据的生命周期。
参考:
- https://www.zhihu.com/question/310212569/answer/581672480
- https://www.infoq.cn/article/MHrhw6x5qK_owazEhEw8
- https://zhuanlan.zhihu.com/p/61167127
- http://pravega.io/docs/latest/pravega-concepts/
4. Lyft 基于Apache Flink的大规模准实时数据分析平台
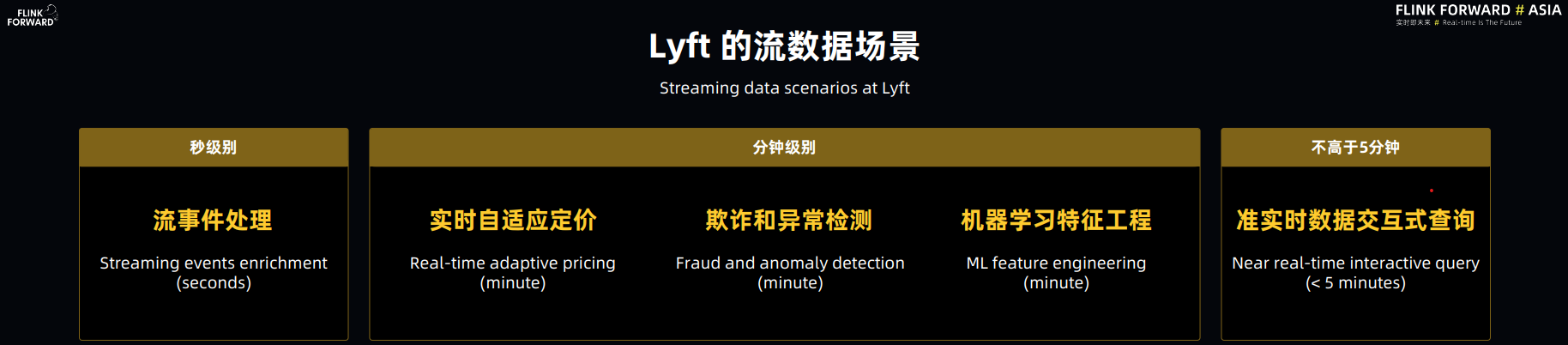
主议题的最后一场是 Flink 实践,是由 Lyft 带来的大规模准实时数据分析平台的分享。这里所说的准实时,指端到端数据延迟不超过 5 分钟,在 Lyft 内部主要用于数据交互式查询。Lyft主要有以下流数据场景:
下图是 Lyft 准实时平台架构图: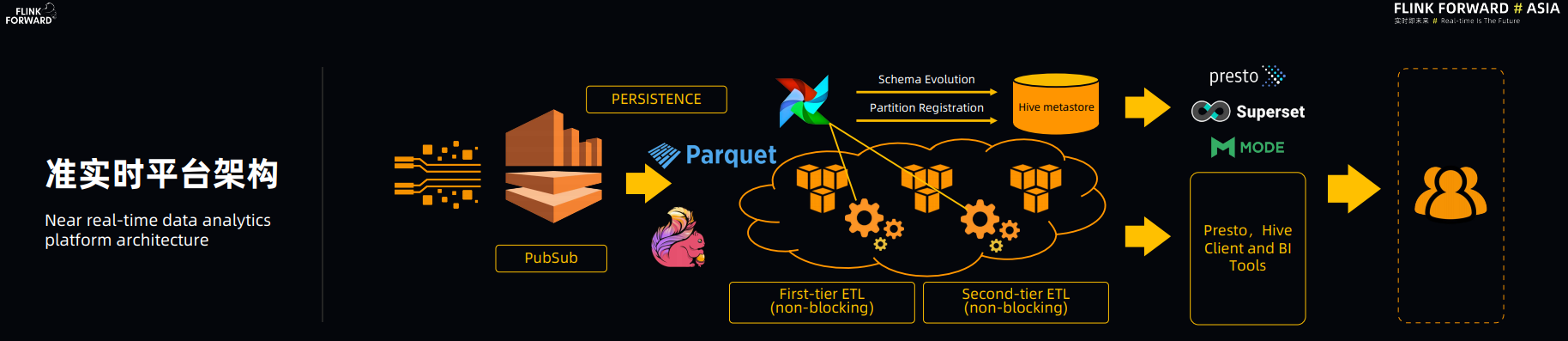
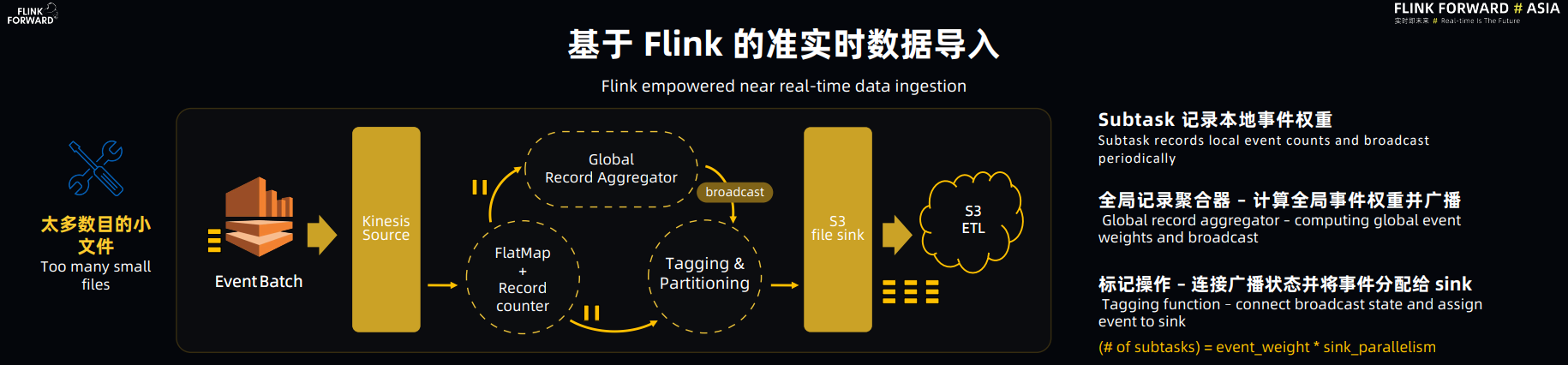
Flink 在整个架构中是用来做流数据注入的,Flink 向 AWS S3 以 Parquet 的格式持久化数据,并以这些原始数据为基础,进行多级 non-blocking 的ETL 加工(压缩去重),建立实时数仓,用于交互式数据查询。
在这个分享中印象深刻的几点:
(1) Flink 的高效性。据 Lyft 的大佬讲,这个新的平台相较于先前基于 Kinesis Client 的 ingestion 相比较,仅数据注入部分的集群就缩减了 10%,所以他们对 Flink 的高效性是非常认可的。
(2) Lyft 也提到,他们花了蛮多精力基于 Flink 的 StreamingFileSink 来解决 Flink 和 ETL 之间 watermark 的同步问题。其实我很希望他们能分享一下为何压缩去重(ETL)部分不也用 Flink 来做。如果是技术上的问题可以帮助 Flink 更好的完善自己。
(3) Lyft 提到 Flink 的重启和部署会对 SLO 造成延迟影响,subtask 停滞会造成整个 pipeline 的停滞以及期望 Flink 能够有一套在 Kubernetes 环境下运行的方案。其实这里提到的几点也在其他的几场企业实践分享中被提到,这些也是当前 Flink 亟待解决的几大痛点。
【关于Flink在failover后的拉起和恢复开销太大的问题,好几个公司都提到了,dstream3/streaming-framework比flink做的要好,可以原地拉起和恢复,而无需从源端进行数据回灌】
分会场
【实时数仓】
1. 美团点评基于 Apache Flink 的实时数仓平台实践
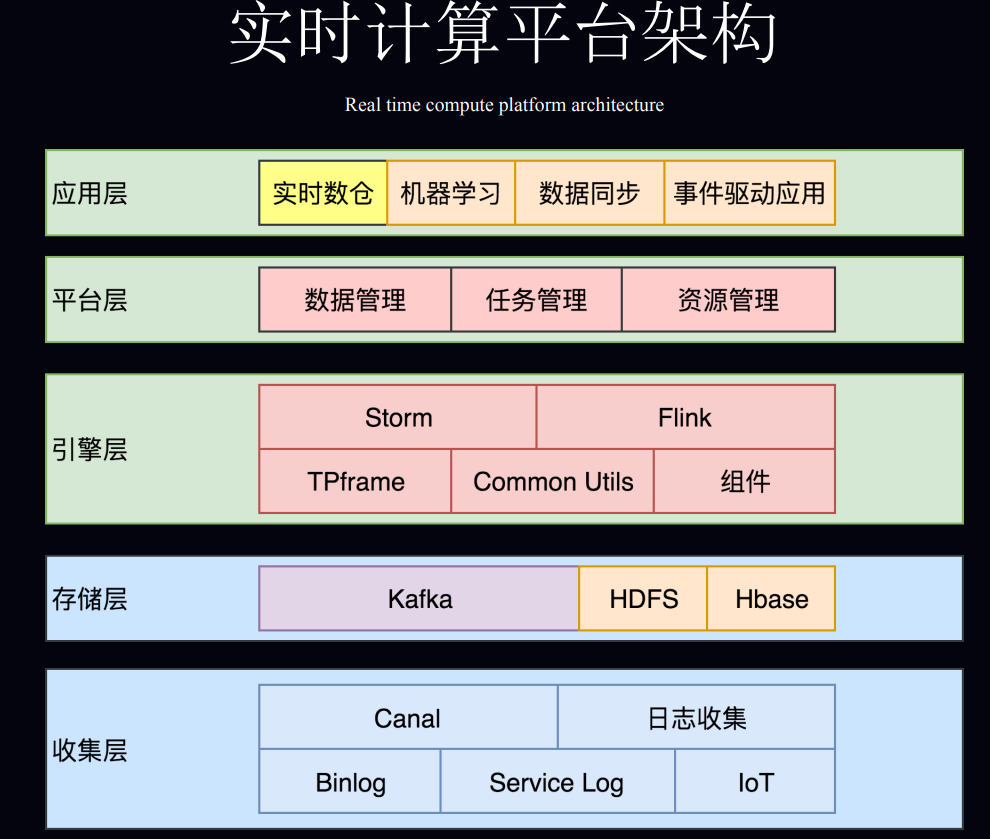
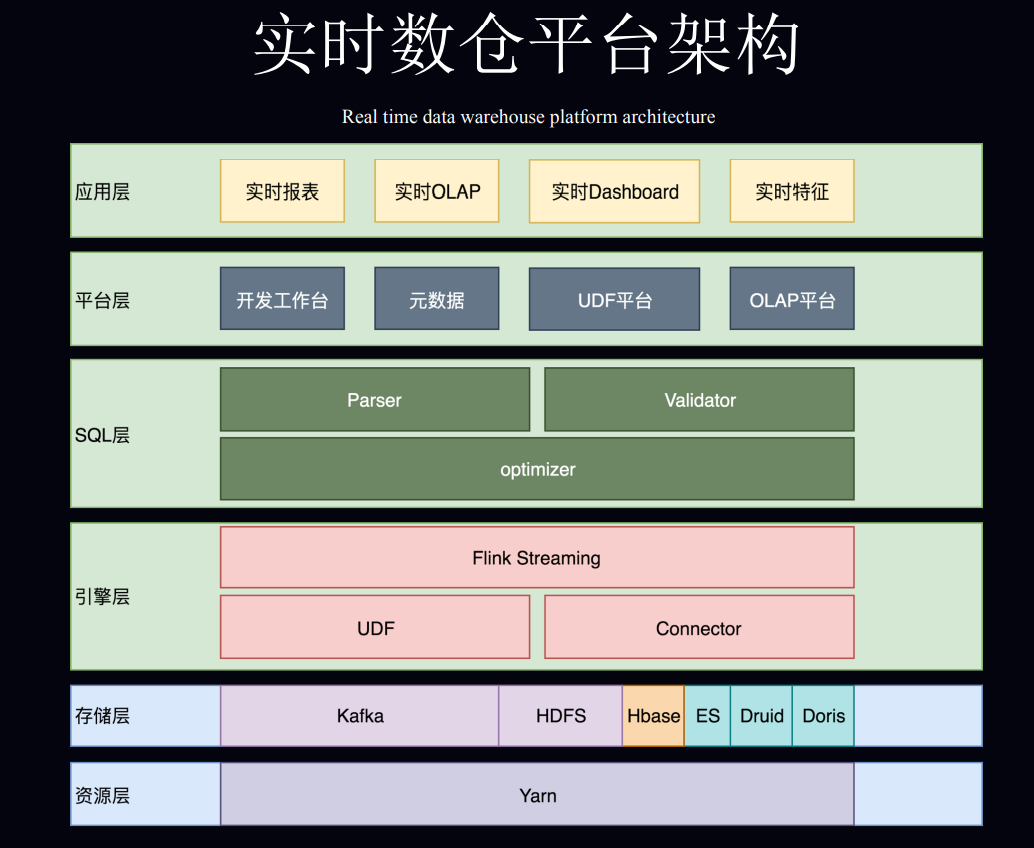
2. 小米流式平台架构演进与实践
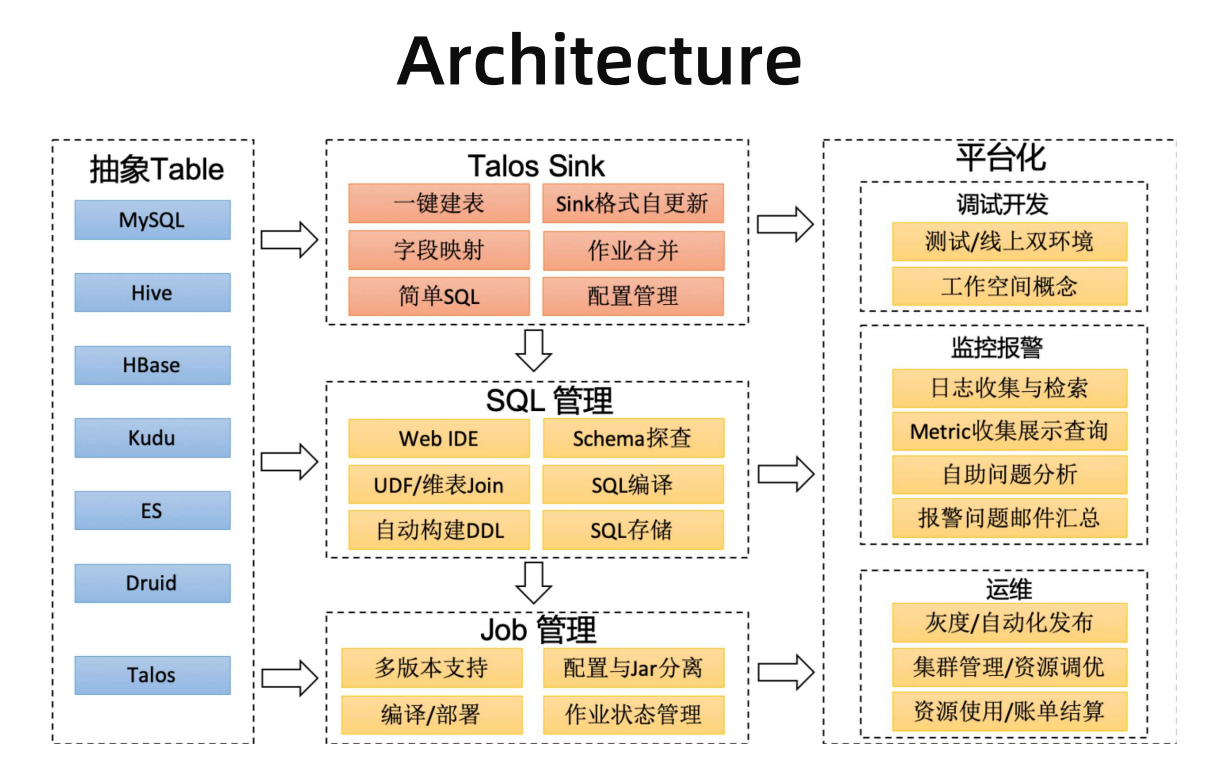
3. OPPO 基于 Apache Flink 的实时数仓实践
从传统的hdfs->hive模式转化为kafka->flink模式
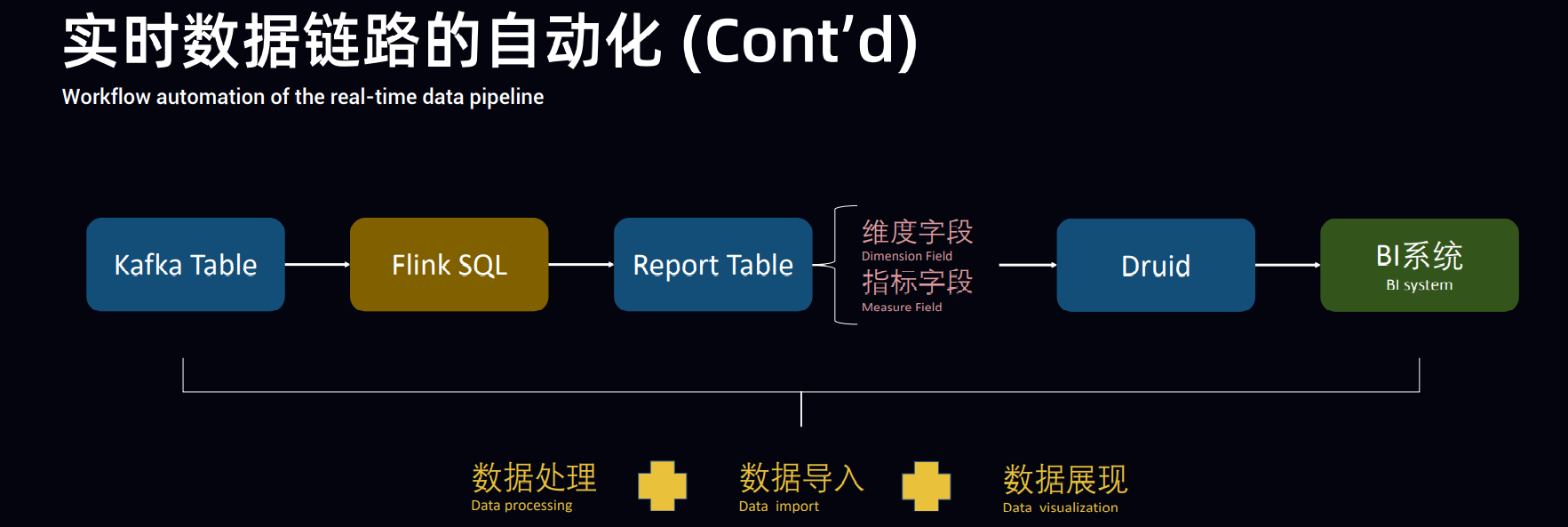
4.趣头条基于 Apache Flink+ClickHouse 构建实时数据分析平台
(1)一条流读取Kafka直接写入ClickHouse
(2)一条流读取Kafka写入Hive,由hive写小时级表?
(3)离线数据则由hive直接导入ClickHouse
【企业实践】
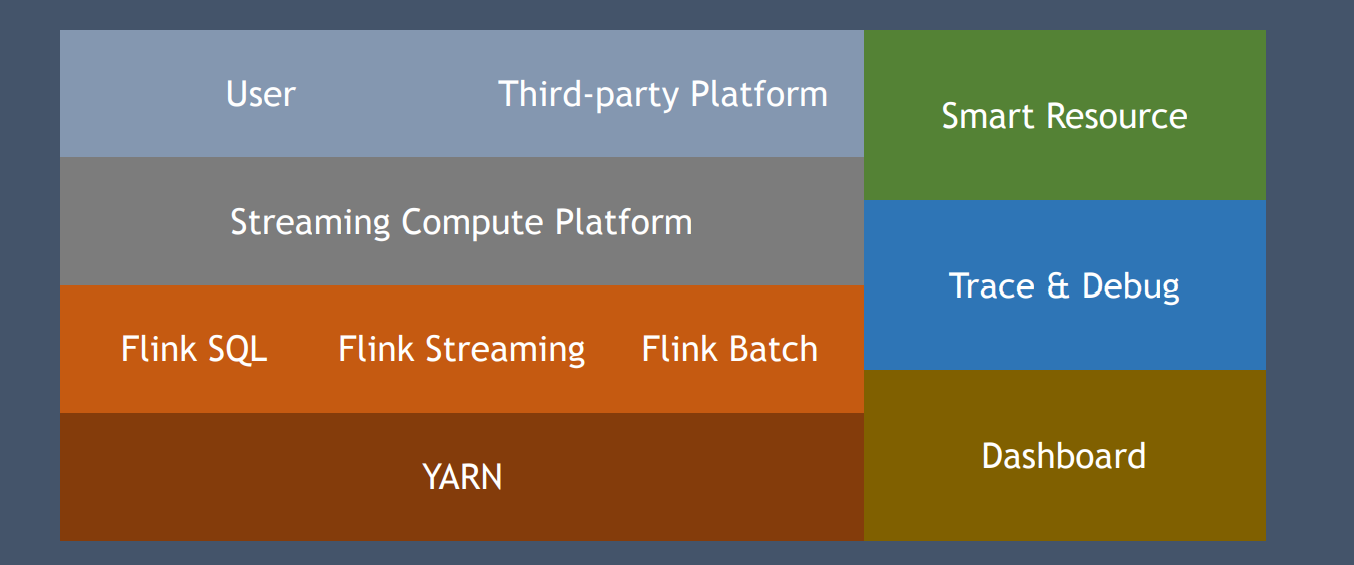
1.Apache Flink 在字节跳动的实践与优化
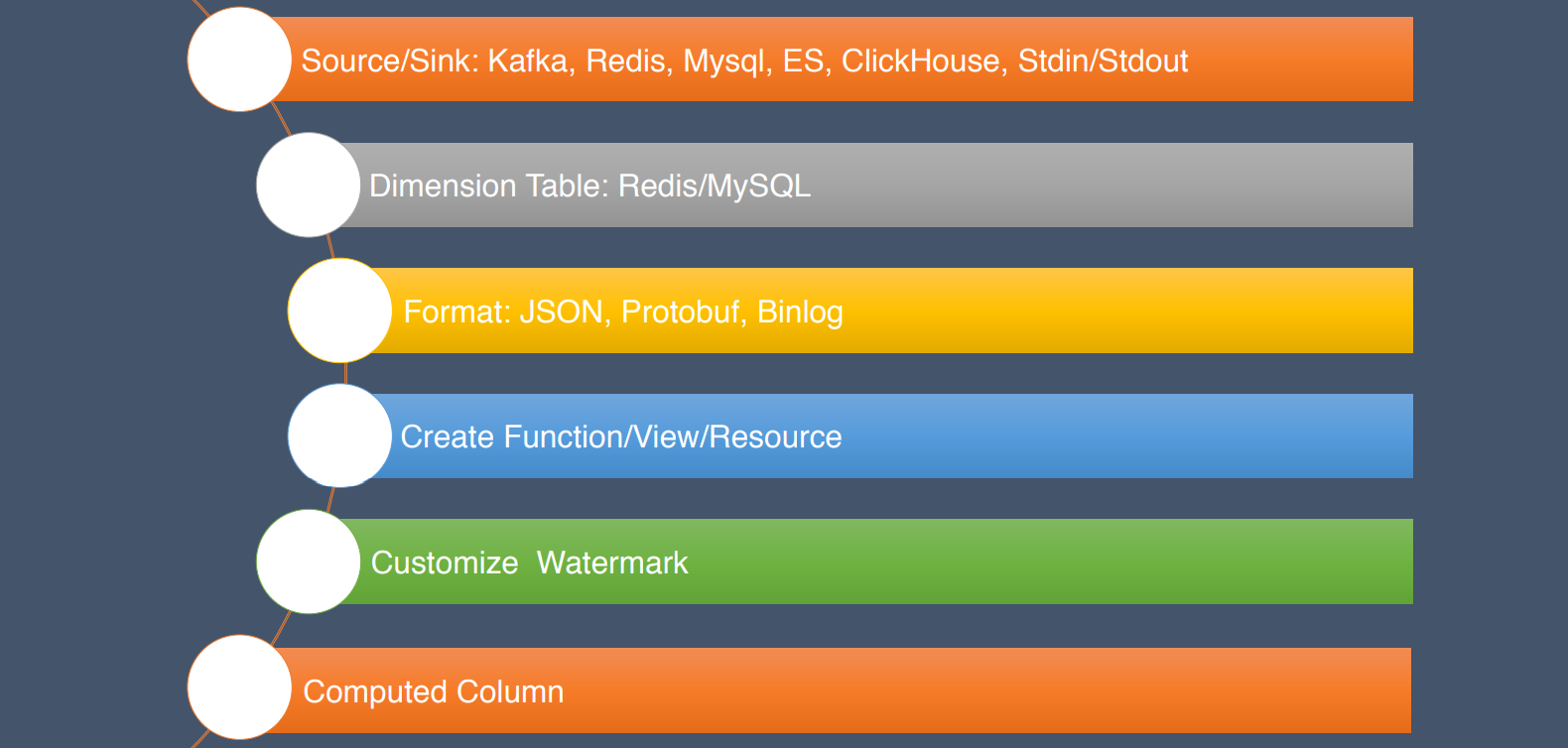
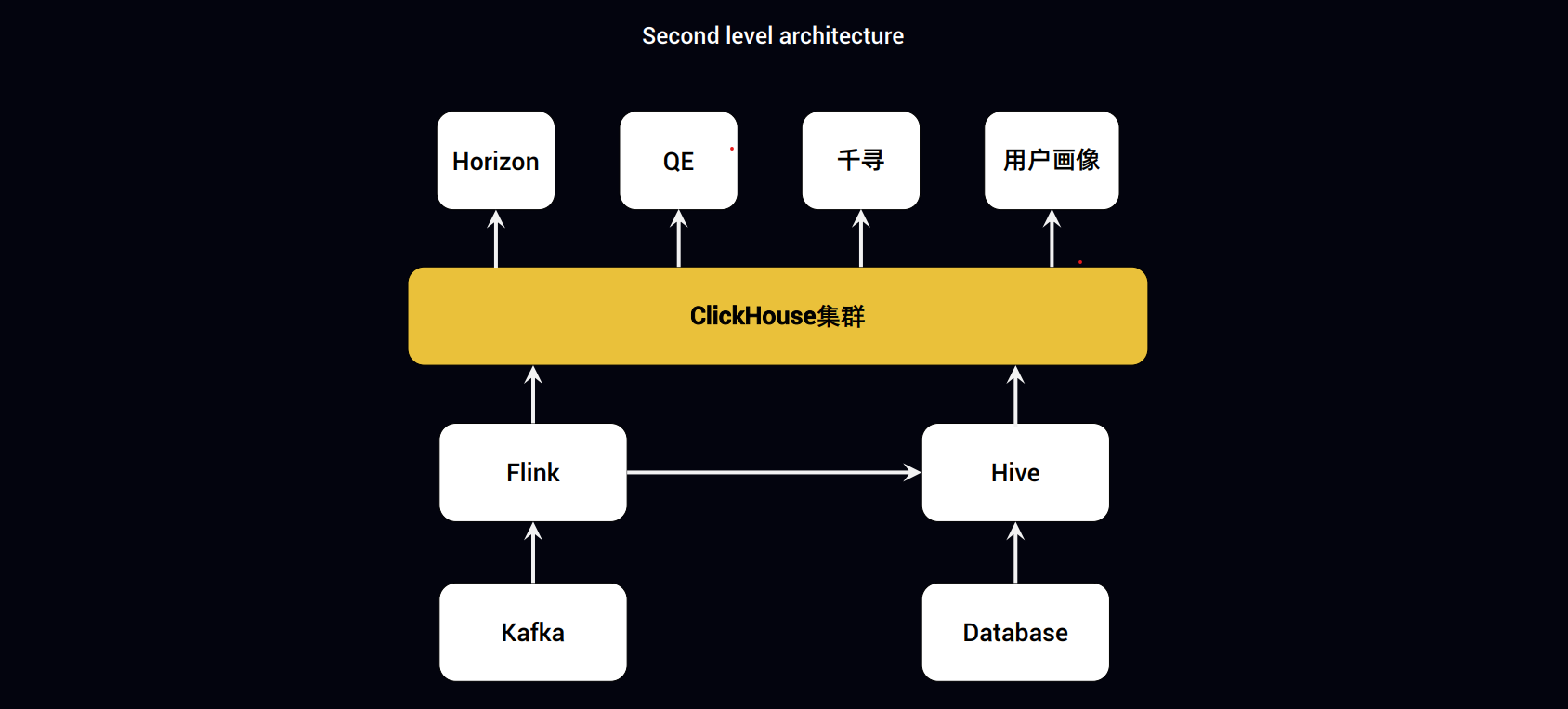
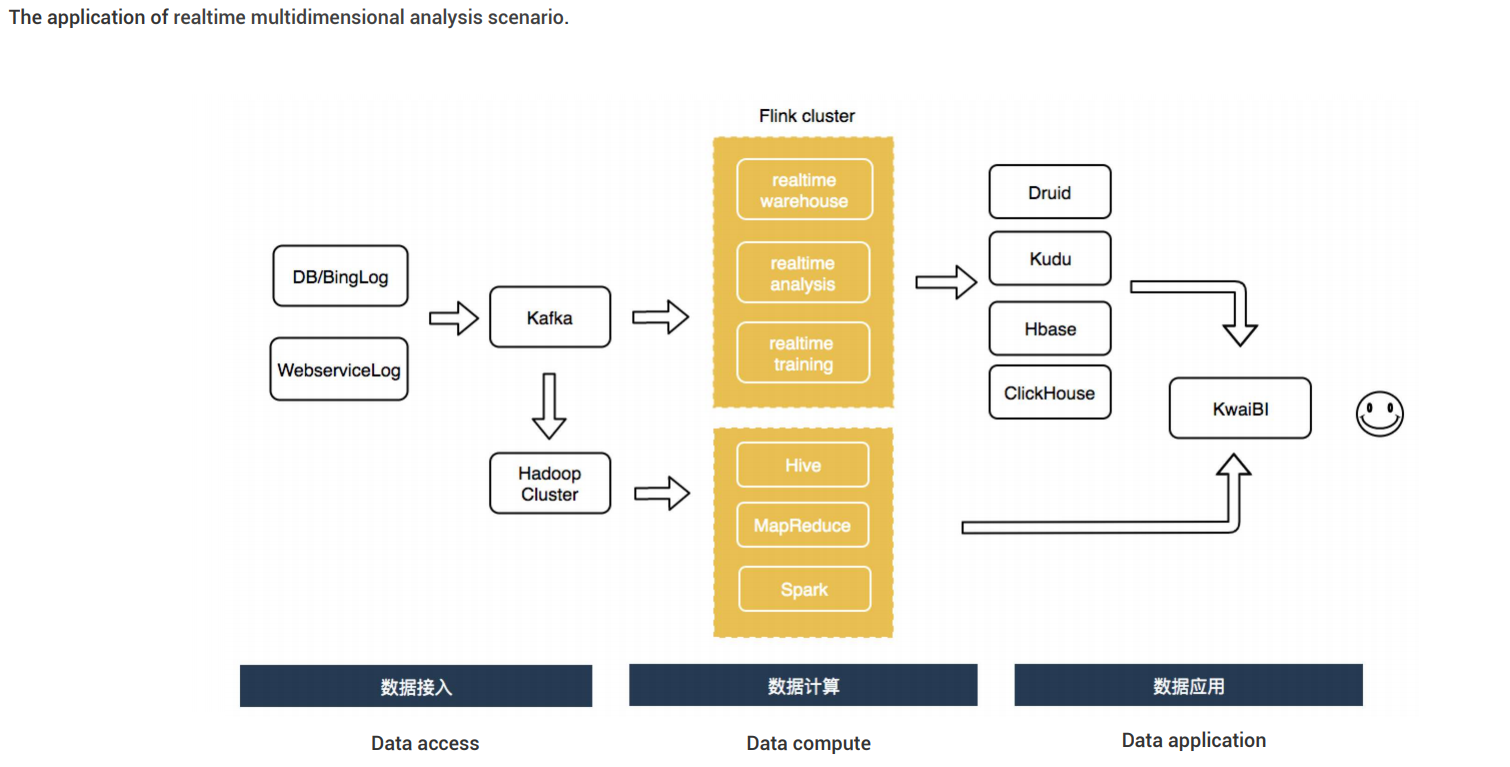
2.Apache Flink在快手实时多维分析场景的应用
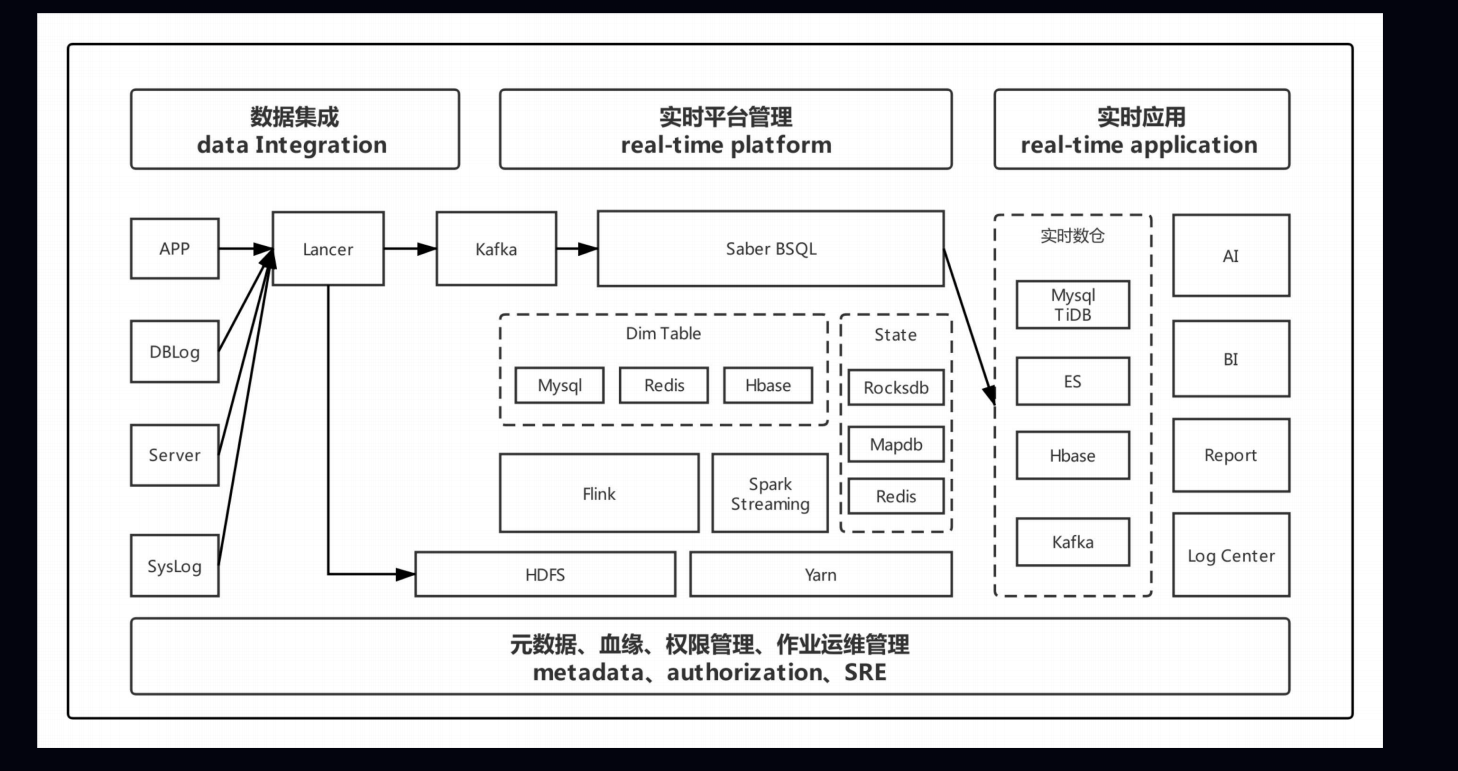
3.bilibili 实时平台的架构与实践
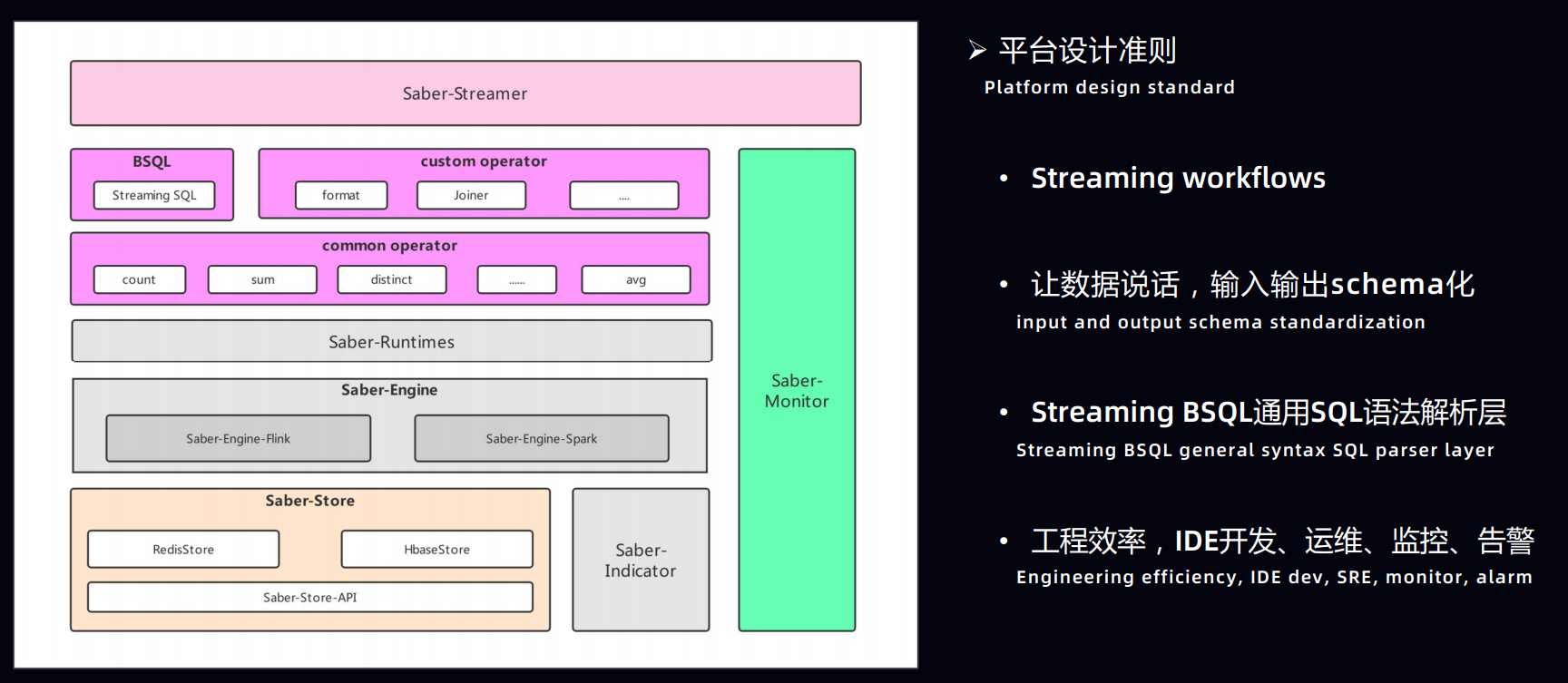
4.基于 Apache Flink 的爱奇艺实时计算平台建设实践
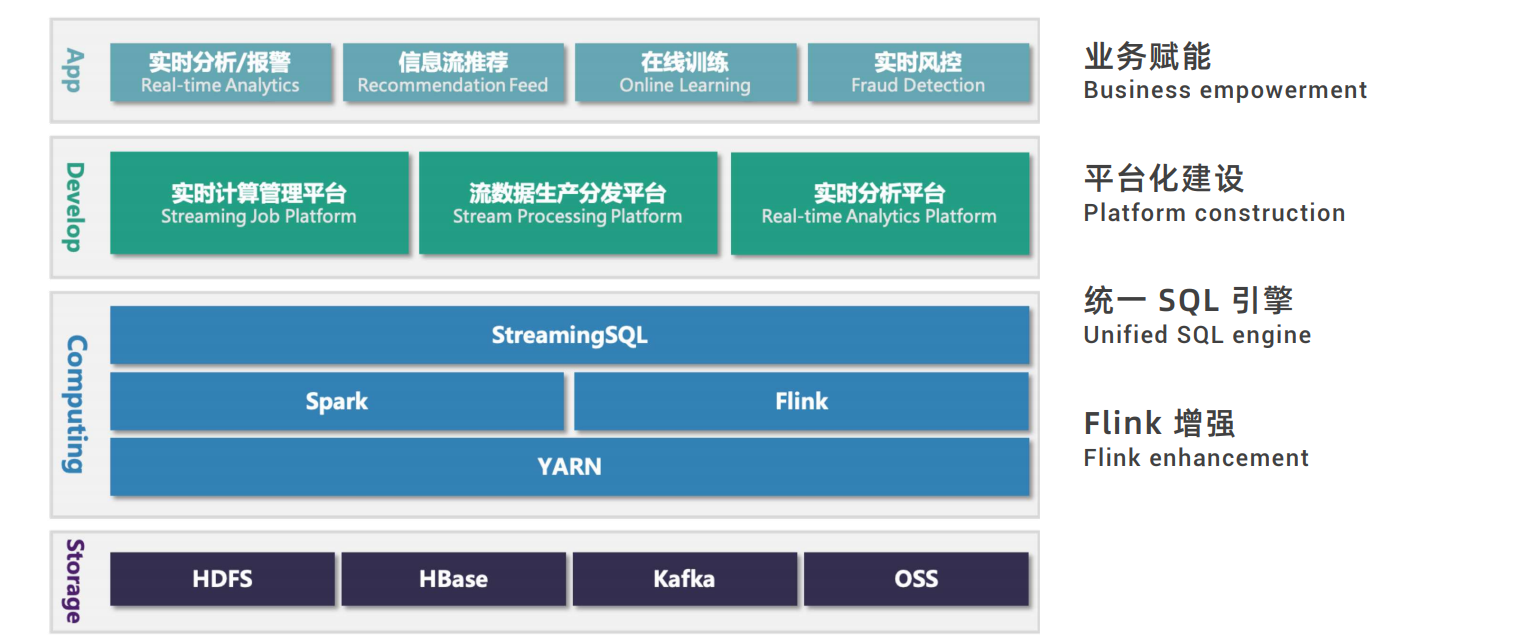
小结
| 数据源 | 计算引擎 | 存储引擎 | 调度引擎 | 查询引擎 |
|---|---|---|---|---|
| Kafka | Spark | HBase | yarn | Hive |
| Database | Flink | RocksDB | k8s | flink-sql |
| File | Hadoop | HDFS | … | my-sql |
| … | ES … | … |
相关链接
主会场视频:https://developer.aliyun.com/live/1657
ppt下载:https://ververica.cn/developers/flink-forward-asia-2019/